この前載せたプログラムにバグがあって、すぐには動かなかないとかそういう問題があったのですが、修正を済ませ、11月までのデータの採取を行いました。モデルを作るときにはデータについて知るということが重要なので、いろいろ統計量とかを出してデータについて馴染んでおきたいと思います。
ユニークアクセス数の推移
この前のは10月までだったので、11月までのユニークアクセス数をプロットしたものを載せてみます。11月は結構好調だったっぽい。
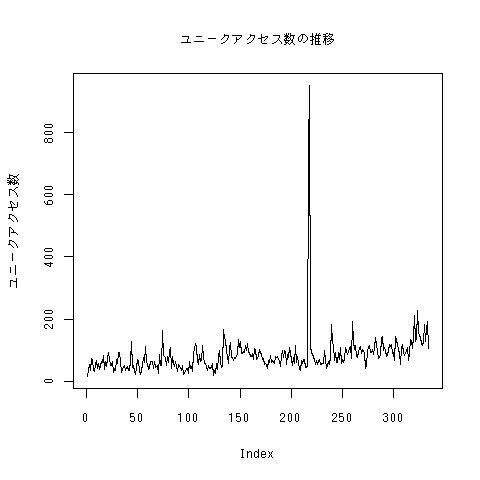
値域の範囲をしぼって表示。

基本統計量
平均、メディアン、分散あたりを調べてみました。
> mean(yan$count) [1] 82.5509 > median(yan$count) [1] 72 > var(yan$count) [1] 4773.708
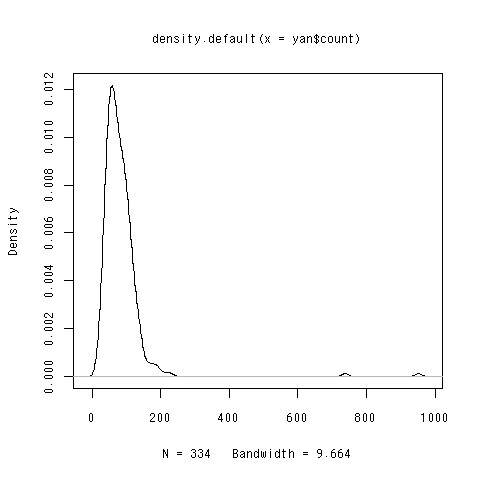
分布
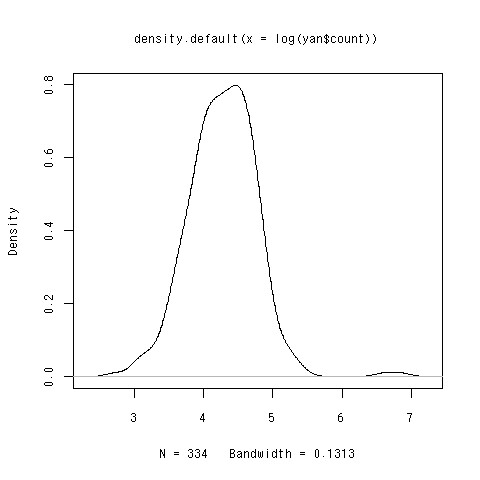
分布の形状を見るために密度トレイスをプロットしてみました。
対数変換するとこんな感じ。
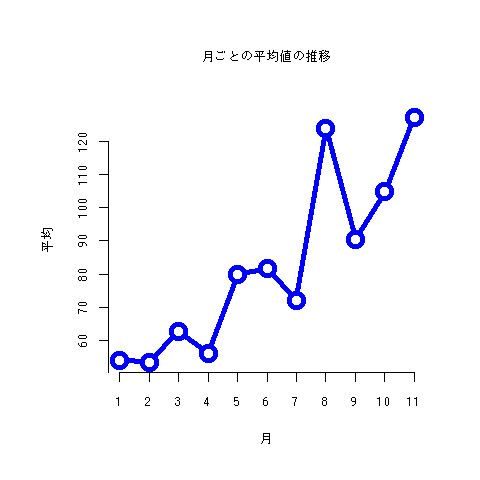
月ごとの平均の推移
月ごとの平均出してみました。8月がはてぶでいっぱい来たときがあるので、平均が引っ張られてる。
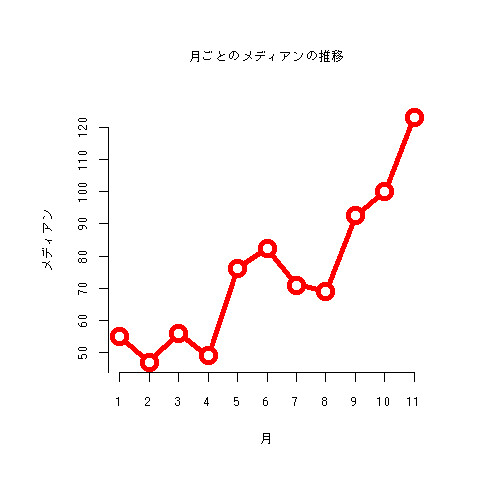
月ごとのメディアンの推移
そういうときはメディアンも見るのがよくやることなので、メディアンのプロットもやってみた。インターン行っててあんまり更新できなかった7、8月は下がってますが、全体的にユニークアクセス数は上昇しているような傾向が見られますね。
曜日ごとの平均の推移
sarima作ったりするかもしれないので、周期性も見たい、ということで曜日ごとの平均をプロットしてみた。

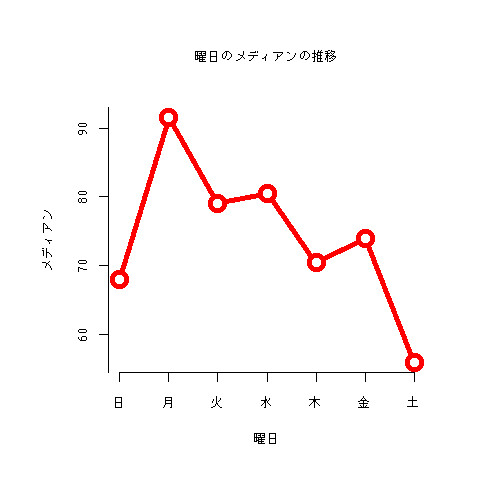
曜日ごとのメディアンの推移
メディアンもついでに。なんとなく周期性がありそうな気がしてきた。週末はやっぱりみんな出かけたりでWebとか見てないからっすかね。
ちょっとしたコード
曜日毎とか月ごとのデータってのを普通にやろうとすると、結構苦労するもんですが、Rはその辺がしっかりしている。applyファミリーの一員であるtapplyを使うと因子ごと*1の統計値とかを出せるので便利である。上のとかは以下のような感じで出した。
png("month_mean.png") par(mar=c(6,6,6,3)) plot(tapply(yan$count,yan$month,mean),pch=21,type="b",xlab="月",ylab="平均",main="月ごとの平均値の推移",axes=F,lwd=5,cex=2,lty=1,col=4) axis(1,1:11,1:11,) axis(2,seq(40,120,by=10)) dev.off() png("month_median.png") par(mar=c(6,6,6,3)) plot(tapply(yan$count,yan$month,median),pch=21,type="b",xlab="月",ylab="メディアン",main="月ごとのメディアンの推移",axes=F,lwd=5,cex=2,lty=1,col=2) axis(1,1:11,1:11,) axis(2,seq(40,120,by=10)) dev.off() week <- c("日","月","火","水","木","金","土") png("week_mean.png") par(mar=c(6,6,6,3)) plot(tapply(yan$count,yan$week,mean),pch=21,type="b",xlab="曜日",ylab="平均",main="曜日の平均値の推移",axes=F,lwd=5,cex=2,lty=1,col=4) axis(1,1:7,week,) axis(2,seq(40,120,by=10)) dev.off() png("week_median.png") par(mar=c(6,6,6,3)) plot(tapply(yan$count,yan$week,median),pch=21,type="b",xlab="曜日",ylab="メディアン",main="曜日のメディアンの推移",axes=F,lwd=5,cex=2,lty=1,col=2) axis(1,1:7,week,) axis(2,seq(40,120,by=10)) dev.off()
id:reposeが知りたいと言っていたちょっとしたテクニックってこういうようなやつのこと?
*1:必ずしも因子である必要はないのかな?