背景 & Disclaimer
- BigQueryは非常に便利で、BigQueryにさえ上がってしまえばSQLで巨大なデータを簡単に相手にできます
- とはいえ、BigQueryに行きつくまでが大変な場合もありえます
- 例: 個人情報を含むsensitiveなデータで、BigQueryに気軽に上げられないケース
- 一時的であっても、相談なしにその手のデータを気軽にアップロードするのはやめてください...
- 数万件程度であれば手元のエクセルで開いて、問題ない行/列だけに絞る、ということもできるが、もっと量が多いデータだとそういうわけにもいかない。そもそも分析はSQLでやりたい
- 公式な分析はデータエンジニアがアップロードしてから開始だけど、一次分析などデータの癖は早めに掴んでおきたいアナリスト / アナリティクスエンジニア
- => 解決例としてDuckDB
- 例: ワンショットで受領した大量のデータ
- 定常的に処理するものなら専用のパイプラインを組んでもよいが、ワンショットの処理なのであまり工数をかけたくない
- => 解決例としてDataflow
- 例: 個人情報を含むsensitiveなデータで、BigQueryに気軽に上げられないケース
- こういったBigQueryを補完してくれるようなデータ処理の技術の例として、DuckDBとDataflowについて紹介します
- 著者はDuckDBとDataflowについてはほとんど使ったことがない人間なので、間違ったことを書いている恐れがあります
- 社内の勉強会で発表する用に調べてみた、程度の内容
- 仕事で使う場合には自分で検証しながらやってください
DuckDB
概念や代表的なユースケース
- DuckDB – An in-process SQL OLAP database management system
- 🦆🦆🦆🦆🦆🦆DuckDB入門🦆🦆🦆🦆🦆🦆
- DuckDBが出たときの論文によると、OLAPかつEmbeddedという立ち位置のツール
- Standalone = クライアント・サーバモデル、Embedded = シングルマシン・インプロセスと思っておくとよさそう

- SQLiteのようにファイルっぽく扱えて、columnar engineのおかげで分析系のクエリも手元で動かすのが得意
- SQLiteより分析系のクエリは圧倒的に早い
- スキーマのauto-detectもあるので、分析前にテーブルのスキーマを決めなくてもさっと分析できる
- 数十カラムあるデータはスキーマ定義だけで疲れてしまいがちなので、割と助かる
- 利用例:
- sensitiveな個人情報が入っているデータでうかつにBigQueryにデータを上げたくない
- とはいえ、納期は結構カツカツ。手元で分析し切れるならそれが一番だけど、エクセルにやらせるには気が重いし、SQLで分析したい
- その他の利用例
- dbt関連のOSSツールでCIでの動作確認などでもよく使われている
- 例: https://github.com/z3z1ma/dbt-osmosis/tree/main/demo_duckdb
- CIからBigQuery参照したくない、PostgreSQLだと
docker-composeなど後始末のことも考えないといけない - DuckDBだとワンファイルだから、考えないといけないことが少なくて済んで楽。
git commitもできる
- dbt関連のOSSツールでCIでの動作確認などでもよく使われている
DuckDBという名前の由来
Frequently Asked Questions – DuckDBより。結構タフな生き物らしい。
Ducks are amazing animals. They can fly, walk and swim. They can also live off pretty much everything. They are quite resilient to environmental challenges. A duck’s song will bring people back from the dead and inspires database research. They are thus the perfect mascot for a versatile and resilient data management system. Also the logo designs itself.
DeepLによる翻訳結果。
アヒルは驚くべき動物だ。飛ぶことも、歩くことも、泳ぐこともできる。また、あらゆるものを食べて生きていくことができる。環境問題にも強い。アヒルの歌は人々を死から蘇らせ、データベース研究を鼓舞する。このように、アヒルは万能で回復力のあるデータ管理システムのマスコットとして最適なのだ。また、ロゴのデザイン自体もそうだ。
使ってみる
インストール。エクセルファイルも読み込めるらしい。
% brew install duckdb
pythonから使いたい場合にはpip install duckdb。クエリ結果をpandasやpolarsのデータフレームとして扱うこともできる。
KaggleのE-Commerce Dataのデータを手元にdata.csvとしてダウンロード。
% head -n 6 data.csv InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United Kingdom 536365,71053,WHITE METAL LANTERN,6,12/1/2010 8:26,3.39,17850,United Kingdom 536365,84406B,CREAM CUPID HEARTS COAT HANGER,8,12/1/2010 8:26,2.75,17850,United Kingdom 536365,84029G,KNITTED UNION FLAG HOT WATER BOTTLE,6,12/1/2010 8:26,3.39,17850,United Kingdom 536365,84029E,RED WOOLLY HOTTIE WHITE HEART.,6,12/1/2010 8:26,3.39,17850,United Kingdom
50万行以上あるデータなので、エクエルだと開くだけでメモリを結構持っていかれる。高度な分析をエクセルでするには気が重いので、DuckDBでやらせよう。
% wc -l data.csv 541910 data.csv
そのままデータを読み込ませると、一部Invalid Input Errorで落ちる。
D SELECT * FROM read_csv_auto('data.csv');
Invalid Input Error: CSV Error on Line: 38250
Original Line:
539492,gift_0001_40,Dotcomgiftshop Gift Voucher ?40.00,1,12/20/2010 10:14,34.04,,United Kingdom
Invalid unicode (byte sequence mismatch) detected.
Possible Solution: Enable ignore errors (ignore_errors=true) to skip this row
file=data.csv
delimiter = , (Auto-Detected)
quote = " (Auto-Detected)
escape = " (Auto-Detected)
new_line = \r\n (Auto-Detected)
header = true (Auto-Detected)
skip_rows = 0 (Auto-Detected)
date_format = (Auto-Detected)
timestamp_format = (Auto-Detected)
null_padding=0
sample_size=20480
ignore_errors=false
all_varchar=0
今回はチュートリアルのノリなので、無視して読み込んでもらう。
D SELECT * FROM read_csv_auto('data.csv', ignore_errors=true) LIMIT 10;
┌───────────┬───────────┬─────────────────────────────────────┬──────────┬────────────────┬───────────┬────────────┬────────────────┐
│ InvoiceNo │ StockCode │ Description │ Quantity │ InvoiceDate │ UnitPrice │ CustomerID │ Country │
│ varchar │ varchar │ varchar │ int64 │ varchar │ double │ int64 │ varchar │
├───────────┼───────────┼─────────────────────────────────────┼──────────┼────────────────┼───────────┼────────────┼────────────────┤
│ 536365 │ 85123A │ WHITE HANGING HEART T-LIGHT HOLDER │ 6 │ 12/1/2010 8:26 │ 2.55 │ 17850 │ United Kingdom │
│ 536365 │ 71053 │ WHITE METAL LANTERN │ 6 │ 12/1/2010 8:26 │ 3.39 │ 17850 │ United Kingdom │
│ 536365 │ 84406B │ CREAM CUPID HEARTS COAT HANGER │ 8 │ 12/1/2010 8:26 │ 2.75 │ 17850 │ United Kingdom │
│ 536365 │ 84029G │ KNITTED UNION FLAG HOT WATER BOTTLE │ 6 │ 12/1/2010 8:26 │ 3.39 │ 17850 │ United Kingdom │
│ 536365 │ 84029E │ RED WOOLLY HOTTIE WHITE HEART. │ 6 │ 12/1/2010 8:26 │ 3.39 │ 17850 │ United Kingdom │
│ 536365 │ 22752 │ SET 7 BABUSHKA NESTING BOXES │ 2 │ 12/1/2010 8:26 │ 7.65 │ 17850 │ United Kingdom │
│ 536365 │ 21730 │ GLASS STAR FROSTED T-LIGHT HOLDER │ 6 │ 12/1/2010 8:26 │ 4.25 │ 17850 │ United Kingdom │
│ 536366 │ 22633 │ HAND WARMER UNION JACK │ 6 │ 12/1/2010 8:28 │ 1.85 │ 17850 │ United Kingdom │
│ 536366 │ 22632 │ HAND WARMER RED POLKA DOT │ 6 │ 12/1/2010 8:28 │ 1.85 │ 17850 │ United Kingdom │
│ 536367 │ 84879 │ ASSORTED COLOUR BIRD ORNAMENT │ 32 │ 12/1/2010 8:34 │ 1.69 │ 13047 │ United Kingdom │
├───────────┴───────────┴─────────────────────────────────────┴──────────┴────────────────┴───────────┴────────────┴────────────────┤
│ 10 rows 8 columns │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘
クエリもいい感じに色を付けてくれる。
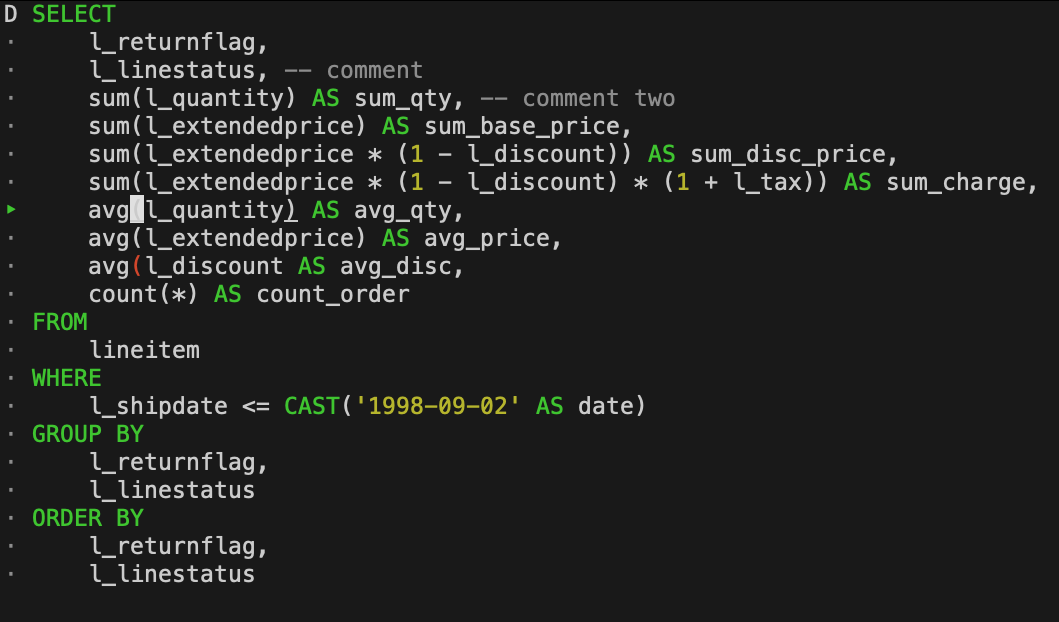
read_csv_autoを使っているので、型はいい感じにdetectしてくれる。もちろん、明示的に型を指定することも可能。ほぼauto-detectで問題ないけど、一部だけ型を変えたいって場合も可能。BigQuery使いの人はvarcharではなくstringのほうが見慣れていると思うけど、ただのaliasなので特に気にしなくてOK。
分析に使うようなクエリも軽快に動く。代表的なWindow Functionsもサポートされているので、めっちゃ凝ったことをしなければ特に問題なさそう。JOINやCTE(WITH句)も当然サポートされている。UNNESTもあるので、中身が配列やSTRUCTでもBigQueryと同様に分析ができる。BigQueryにデータがロードされるまでの間はDuckDBで分析をして、BigQueryにデータがロードされたらクエリを最小限の書き換えで本来の分析に当ててみる、ということが簡単にできる。
D SELECT
Country,
COUNT(DISTINCT CustomerID) AS customers_count,
SUM(UnitPrice * Quantity) AS gmv,
FROM read_csv_auto('data.csv', ignore_errors=true)
GROUP BY Country
ORDER BY gmv DESC
LIMIT 10;
┌────────────────┬─────────────────┬────────────────────┐
│ Country │ customers_count │ gmv │
│ varchar │ int64 │ double │
├────────────────┼─────────────────┼────────────────────┤
│ United Kingdom │ 3950 │ 8187806.36399906 │
│ Netherlands │ 9 │ 284661.53999999986 │
│ EIRE │ 3 │ 263276.82 │
│ Germany │ 95 │ 221698.21000000025 │
│ France │ 87 │ 197403.90000000026 │
│ Australia │ 9 │ 137077.26999999996 │
│ Switzerland │ 21 │ 56385.34999999998 │
│ Spain │ 31 │ 54774.58 │
│ Belgium │ 25 │ 40910.96 │
│ Sweden │ 8 │ 36595.91 │
├────────────────┴─────────────────┴────────────────────┤
│ 10 rows 3 columns │
└───────────────────────────────────────────────────────┘
分析した結果のテーブルに名前を付けることもできる。
D CREATE TABLE tmp AS (SELECT
Country,
COUNT(DISTINCT CustomerID) AS customers_count,
SUM(UnitPrice * Quantity) AS gmv,
FROM read_csv_auto('data.csv', ignore_errors=true)
GROUP BY Country
ORDER BY gmv DESC);
D SELECT * FROM tmp LIMIT 10;
┌────────────────┬─────────────────┬────────────────────┐
│ Country │ customers_count │ gmv │
│ varchar │ int64 │ double │
├────────────────┼─────────────────┼────────────────────┤
│ United Kingdom │ 3950 │ 8187806.363999059 │
│ Netherlands │ 9 │ 284661.53999999986 │
│ EIRE │ 3 │ 263276.82 │
│ Germany │ 95 │ 221698.21000000028 │
│ France │ 87 │ 197403.90000000026 │
│ Australia │ 9 │ 137077.26999999996 │
│ Switzerland │ 21 │ 56385.34999999998 │
│ Spain │ 31 │ 54774.58000000001 │
│ Belgium │ 25 │ 40910.96000000001 │
│ Sweden │ 8 │ 36595.91 │
├────────────────┴─────────────────┴────────────────────┤
│ 10 rows 3 columns │
└───────────────────────────────────────────────────────┘
1週間〜一ヶ月などある程度の期間、分析で使いたい場合
一週間以上同じデータを扱う必要がある場合、複数のテーブルを触ることも多いだろう。どういうテーブルがあったかを調べたい、このテーブルのschemaどういうのだったけ、が知りたい場合はSHOWやDESCRIBEを使うといい。
D show; ┌──────────┬─────────┬─────────┬─────────────────────────────────┬───────────────────────────┬───────────┐ │ database │ schema │ name │ column_names │ column_types │ temporary │ │ varchar │ varchar │ varchar │ varchar[] │ varchar[] │ boolean │ ├──────────┼─────────┼─────────┼─────────────────────────────────┼───────────────────────────┼───────────┤ │ memory │ main │ tmp │ [Country, customers_count, gmv] │ [VARCHAR, BIGINT, DOUBLE] │ false │ └──────────┴─────────┴─────────┴─────────────────────────────────┴───────────────────────────┴───────────┘ D show all tables; ┌──────────┬─────────┬─────────┬─────────────────────────────────┬───────────────────────────┬───────────┐ │ database │ schema │ name │ column_names │ column_types │ temporary │ │ varchar │ varchar │ varchar │ varchar[] │ varchar[] │ boolean │ ├──────────┼─────────┼─────────┼─────────────────────────────────┼───────────────────────────┼───────────┤ │ memory │ main │ tmp │ [Country, customers_count, gmv] │ [VARCHAR, BIGINT, DOUBLE] │ false │ └──────────┴─────────┴─────────┴─────────────────────────────────┴───────────────────────────┴───────────┘
D DESCRIBE tmp; ┌─────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐ │ column_name │ column_type │ null │ key │ default │ extra │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├─────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤ │ Country │ VARCHAR │ YES │ │ │ │ │ customers_count │ BIGINT │ YES │ │ │ │ │ gmv │ DOUBLE │ YES │ │ │ │ └─────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘
「CLI慣れてないよ」って人はGUIも提供されているので、好きなものを使うとよい。

BigQueryのテーブルのプレビューのノリでデータを眺めることができる。

脱線だが、BigQueryの画面内でもクエリ結果をグラフ表示することができるが、同様のことがDuckDBのGUIからもできる。綺麗なグラフを表示してくれるので、結構テンションが上がった。
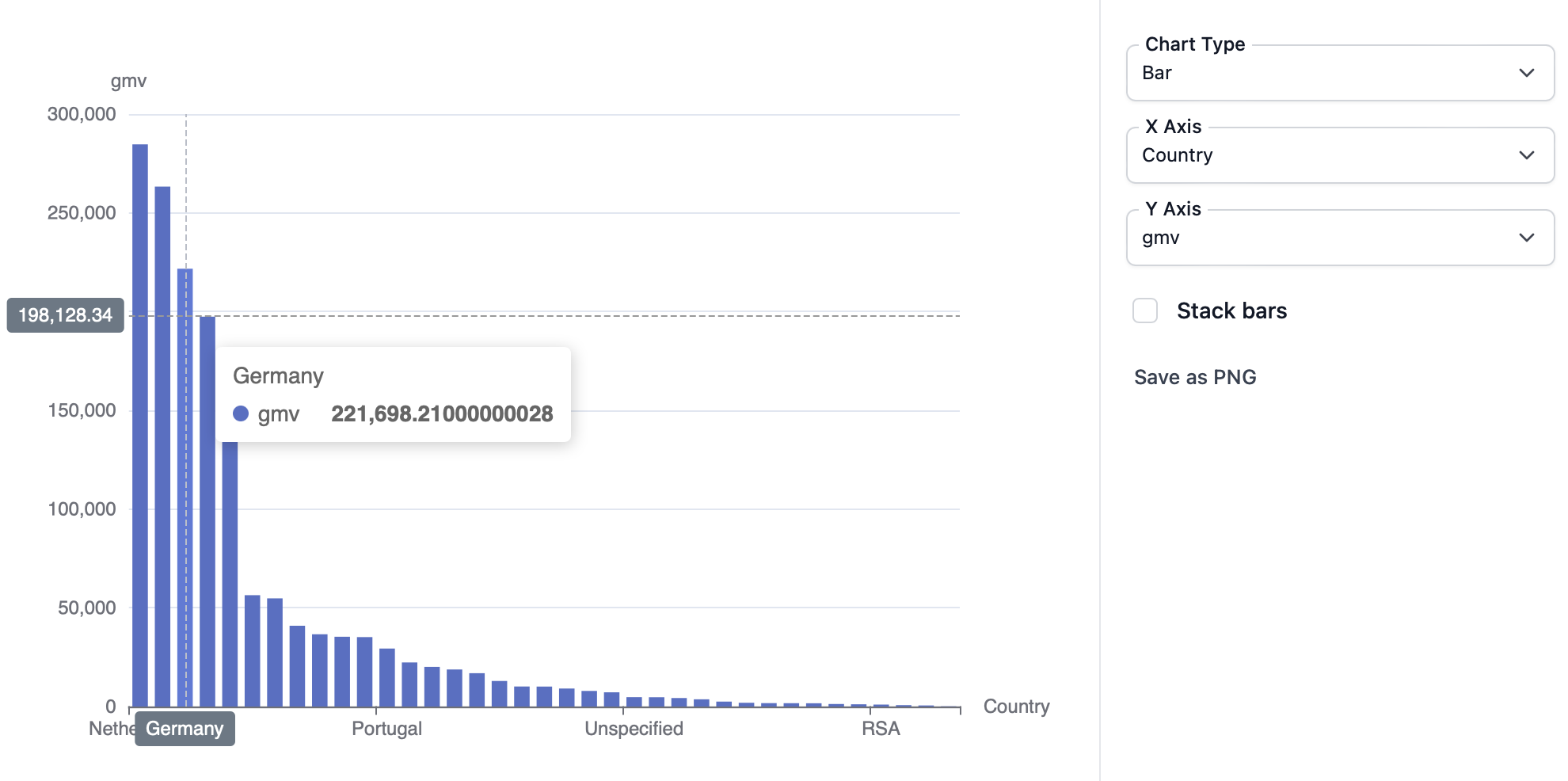
DuckDBは基本的にin-memoryのDBなので、何もしないとセッションが終わったら一時テーブルは消えてしまう。後始末をする必要がないのはそれはそれでよいが、PCの再起動などで分析結果を入れていたテーブルが消えてしまうのは困る。
D DESCRIBE tmp; ┌─────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐ │ column_name │ column_type │ null │ key │ default │ extra │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├─────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤ │ Country │ VARCHAR │ YES │ │ │ │ │ customers_count │ BIGINT │ YES │ │ │ │ │ gmv │ DOUBLE │ YES │ │ │ │ └─────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘ D % duckdb v0.10.3 70fd6a8a24 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. D DESCRIBE tmp; Catalog Error: Table with name tmp does not exist! Did you mean "pg_am"?
実行時にファイル名を指定すると、テーブルをファイルに保存してくれる。DuckDBを一時終了してもファイルにテーブルの結果が残っている。
% duckdb my_database.db
v0.10.3 70fd6a8a24
Enter ".help" for usage hints.
D DESCRIBE tmp;
Catalog Error: Table with name tmp does not exist!
Did you mean "pg_am"?
D CREATE TABLE tmp AS (SELECT
Country,
COUNT(DISTINCT CustomerID) AS customers_count,
SUM(UnitPrice * Quantity) AS gmv,
FROM read_csv_auto('data.csv', ignore_errors=true)
GROUP BY Country
ORDER BY gmv DESC);
D DESCRIBE tmp;
┌─────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ Country │ VARCHAR │ YES │ │ │ │
│ customers_count │ BIGINT │ YES │ │ │ │
│ gmv │ DOUBLE │ YES │ │ │ │
└─────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘
D .exit
% duckdb my_database.db
v0.10.3 70fd6a8a24
Enter ".help" for usage hints.
D DESCRIBE tmp;
┌─────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐
│ column_name │ column_type │ null │ key │ default │ extra │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├─────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤
│ Country │ VARCHAR │ YES │ │ │ │
│ customers_count │ BIGINT │ YES │ │ │ │
│ gmv │ DOUBLE │ YES │ │ │ │
└─────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘
D .exit
途中からファイルを開くことももちろんできる。
% duckdb v0.10.3 70fd6a8a24 Enter ".help" for usage hints. Connected to a transient in-memory database. Use ".open FILENAME" to reopen on a persistent database. D .open my_database.db D DESCRIBE tmp; ┌─────────────────┬─────────────┬─────────┬─────────┬─────────┬─────────┐ │ column_name │ column_type │ null │ key │ default │ extra │ │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ ├─────────────────┼─────────────┼─────────┼─────────┼─────────┼─────────┤ │ Country │ VARCHAR │ YES │ │ │ │ │ customers_count │ BIGINT │ YES │ │ │ │ │ gmv │ DOUBLE │ YES │ │ │ │ └─────────────────┴─────────────┴─────────┴─────────┴─────────┴─────────┘ D SELECT * FROM tmp LIMIT 10; ┌────────────────┬─────────────────┬────────────────────┐ │ Country │ customers_count │ gmv │ │ varchar │ int64 │ double │ ├────────────────┼─────────────────┼────────────────────┤ │ United Kingdom │ 3950 │ 8187806.36399906 │ │ Netherlands │ 9 │ 284661.53999999986 │ │ EIRE │ 3 │ 263276.82 │ │ Germany │ 95 │ 221698.21000000028 │ │ France │ 87 │ 197403.90000000023 │ │ Australia │ 9 │ 137077.27 │ │ Switzerland │ 21 │ 56385.34999999998 │ │ Spain │ 31 │ 54774.58 │ │ Belgium │ 25 │ 40910.96 │ │ Sweden │ 8 │ 36595.909999999996 │ ├────────────────┴─────────────────┴────────────────────┤ │ 10 rows 3 columns │ └───────────────────────────────────────────────────────┘
便利なCLIツールとして使う
STDIN(標準入力)でデータを受け取って、SQLで加工した上でcsvやjsonとして出力する、ということが簡単にできる。jqのsyntaxは毎回ぐぐらないと分からない人が多いと思うけど(自分もです)、SQLはデータエンジニアならサクサク書けると思うので、便利。レスポンスの結果を何かしらの他の結果とJOINしたいという場合もSQL なら簡単。
% cat data.csv | duckdb -csv -c "SELECT * FROM read_csv_auto('/dev/stdin', ignore_errors=true) LIMIT 3"
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country
536365,85123A,"WHITE HANGING HEART T-LIGHT HOLDER",6,"12/1/2010 8:26",2.55,17850,"United Kingdom"
536365,71053,"WHITE METAL LANTERN",6,"12/1/2010 8:26",3.39,17850,"United Kingdom"
536365,84406B,"CREAM CUPID HEARTS COAT HANGER",8,"12/1/2010 8:26",2.75,17850,"United Kingdom"
% cat data.csv | duckdb -json -c "SELECT * FROM read_csv_auto('/dev/stdin', ignore_errors=true) LIMIT 3"
[{"InvoiceNo":"536365","StockCode":"85123A","Description":"WHITE HANGING HEART T-LIGHT HOLDER","Quantity":6,"InvoiceDate":"12/1/2010 8:26","UnitPrice":2.55,"CustomerID":17850,"Country":"United Kingdom"},
{"InvoiceNo":"536365","StockCode":"71053","Description":"WHITE METAL LANTERN","Quantity":6,"InvoiceDate":"12/1/2010 8:26","UnitPrice":3.39,"CustomerID":17850,"Country":"United Kingdom"},
{"InvoiceNo":"536365","StockCode":"84406B","Description":"CREAM CUPID HEARTS COAT HANGER","Quantity":8,"InvoiceDate":"12/1/2010 8:26","UnitPrice":2.75,"CustomerID":17850,"Country":"United Kingdom"}]
APIのレスポンス結果であるJSONを入力として受け取って、SQLで加工/集計する、ということも簡単にできる。
% curl -s https://api.github.com/users | duckdb -csv -c "SELECT login,id,avatar_url FROM read_json_auto('/dev/stdin', ignore_errors=true) LIMIT 3"
login,id,avatar_url
mojombo,1,https://avatars.githubusercontent.com/u/1?v=4
defunkt,2,https://avatars.githubusercontent.com/u/2?v=4
pjhyett,3,https://avatars.githubusercontent.com/u/3?v=4
様々なOSで簡単にインストールできて、SQLさえ書ければいいので、他の同僚にもオススメしやすいのがよい(面倒だと布教しにくい)。
所感
- 手元にあるデータをさっと分析するのには便利
- pandasのAPIを頑張って思い出さなくても、SQLさえ書ければいつもの感じで分析できる
- 扱う適切なデータ量の範囲は数百MB〜数GBくらい?
- 個人の感想です
- これ以上になると、個人のPCではクエリ最適化が必要になることが多そう
- 手元でクエリ最適化を頑張るよりはCloudのDWHでごりっとやるほうがトータルの工数は少ないと思う
- 適材適所
- CLIツールとしても結構使い勝手がよい
- jq職人芸からの脱却
- 個人的にはCLIツールとして結構気に入った
- dbt関連のOSSとしても使い勝手がよい
参考
- DuckDB メモ
- DuckDB as jq
- DuckDB as the New jq - Paul Gross’s Blog
- DuckDBでお手軽!データフェデレーション - Techtouch Developers Blog
- 異なるデータソースをDuckDB上でJOIN
Dataflow
- おおむねDataflowを徹底解説! - G-gen Tech Blogを読むとよい
- 元々、バッチ処理とストリーミング処理の両方を処理できるApache BeamというOSSがあり、DataflowはGoogle Cloudが提供するマネージドな実行環境に関連するサービス
- 処理の内容に応じて、必要な分のコンピューティングのリソースを勝手に調達 / 後片付けしてくれる
代表的なユースケース
- リアルタイムなデータの取り込み
- Pub/Subからデータを受け取って、色々やった後にBigQueryやBigTableなどに書き込み可視化などを行なう
- 例: 一時間くらいのウィンドウ幅を持ちながら、時々刻々と変わるSNS上のトレンド分析を行なう
- Dataflowの中やることが多い色々なこと:
- データのバリデーション
- Pub/Subのat-least-onceに対して、重複レコードの削除
- データストアへの書き込み。BigQueryのような典型的なデータストアについては関数が用意されている
- 自前でやろうとすると、Pub/Subの流量に応じてコンピューティングリソースの確保をするのは面倒になりがち
- 特に一台のマシンで済まない場合。巨大な一台のインスタンスを用意してもいいが、流量が少ない時間帯だとリソースの無駄が発生してしまう
- Pub/Subからデータを受け取って、色々やった後にBigQueryやBigTableなどに書き込み可視化などを行なう
- データストア間の移行や同期
- Google Cloud側で便利なテンプレートが用意されており、MySQL / PostgresSQL / MongoDBなどを数クリックでBigQueryやCloud Spannerに移行することができる
- CDCを元にDatastreamからCloud Strorageへのデータ取り込みを元に、DataflowでBigQueryにリアルタイムなデータ同期もできる
具体例
具体例と書きつつ、自社で扱いそうな具体例を持ってきたので、あまり世の中の典型的な事例にはなってないのは見逃してください。世の中的にはリアルタイムなデータ処理/分析が多いんだと思います。
- 複数の圧縮済みのcsvファイルがGCS上に配置されており、分析用にBigQueryのテーブルとしてloadしたい
- これだけであれば典型的な要件であり、Dataflowを持ち出すまでもない
- 圧縮済みのcsvであっても
bq loadコマンドでloadできる - 複数ファイルあってもワイルドカードでloadできる
- 圧縮済みのcsvであっても
- しかし、現実のデータエンジニアリングは簡単でないことも多い...
- 例: 諸事情により、GCSにデータが置いてあるロケーションとBigQueryに配置したいロケーションが異なる
bq loadだと動かない
- 例: 元ファイルがsjisになっており、そのままloadするとBigQuery上で文字化けしてしまう
- BigQueryにデータをロードする前に何とかしないといけない
- 手元でnkfをかければいいが、そもそもデータを手元にダウンロードしたくない(セキュリティ的な観点)
- 例: データのvalidationがSQLでは簡単に書けない、あるいはアプリケーション側で用いられているvalidationのロジック(in Java or Python)があり、それを使い回したい
- 例: 自由入力のテキスト欄があり、形態素解析やキーワード抽出を前処理として行ないたい
- 素朴なSQLではやりにくい
- BigQuery Remote Functionsを使えばできなくもないが...
- 例: CSVの列の情報を読み取った上で特徴量を付与したい、あるいは予測確率も付与したい
- 例: 諸事情により、GCSにデータが置いてあるロケーションとBigQueryに配置したいロケーションが異なる
- 最近だとCloud Run ジョブなどでやるのが適しているかもしれない
- とはいえ、Cloud Run ジョブはDockerイメージを格納するArtifact Registryの準備なども必要
- ワンショットでデータを上げたい場合はDataflowのほうが気軽にできる側面もまだまだありそう
GCSにあるsjisのファイルの文字コードを変換しながら、BigQueryにデータをロードしていくコード例。
import logging from datetime import date import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions, _BeamArgumentParser class BeamOptions(PipelineOptions): @classmethod def _add_argparse_args(cls, parser: _BeamArgumentParser) -> None: parser.add_argument("--input", type=str, required=True) # ref: https://beam.apache.org/releases/pydoc/2.41.0/apache_beam.coders.coders.html#apache_beam.coders.coders.Coder # ref: https://note.com/nitta_new/n/n3b00ece1d17d class StrCp932Coder(beam.coders.Coder): def encode(self, value): return value.encode("cp932") def decode(self, value): return value.decode("cp932") def is_deterministic(self): return True def run_pipeline(options: BeamOptions): logger = logging.getLogger(__name__) table_schema = { "fields": [ {"name": "order_date", "type": "date", "mode": "NULLABLE"}, {"name": "user_id", "type": "string", "mode": "NULLABLE"}, {"name": "quantity", "type": "integer", "mode": "NULLABLE"}, {"name": "amount", "type": "integer", "mode": "NULLABLE"}, ] } output_table_spec = "my-project:my_dataset.my_table" def csv_to_dict(line): elements = line.split(",") result = dict() for index, schema in enumerate(table_schema["fields"]): column_name = schema["name"] column_type = schema["type"] try: element = elements[index] except IndexError: logger.error(f'IndexError: index: {index}, line: "{line}"') element = None if element is not None: if column_type == "datetime": date_parts = [int(value) for value in element.split("-")] element = date(*date_parts) elif column_type == "integer": element = int(element) result[column_name] = element return result with beam.Pipeline(options=options) as p: raw_data = p | "Find files" >> beam.io.ReadFromText( options.input, compression_type="gzip", coder=StrCp932Coder() ) transformed_data = raw_data | "Transform data" >> beam.Map(csv_to_dict) transformed_data | "Write to BigQuery" >> beam.io.WriteToBigQuery( output_table_spec, schema=table_schema, create_disposition=beam.io.BigQueryDisposition.CREATE_NEVER, write_disposition=beam.io.BigQueryDisposition.WRITE_TRUNCATE, ) def main(): logging.basicConfig(level=logging.ERROR) options = BeamOptions() run_pipeline(options) if __name__ == "__main__": main()
実行するときはこういう感じで動かす。Dataflowじゃなくて手元で動かしたい場合には--runner Directを指定するとよい。
% python main.py --region asia-northeast1 \ --input "gs://my-bucket/2024060*.csv.gz" \ --runner DataflowRunner \ --project my-project \ --temp_location gs://my-bucket/dataflow/temp/main_job
実行中、裏側ではこういうGCEのインスタンスが立ち上がってくる。処理が終わったら、インスタンスも消してくれる。この辺はOSSのBeamを使うだけでは享受できないDataflowのよさの一つ。


--temp_locationオプションはデータ変換したものをBigQueryにloadする用の一時ファイル置き場の指定になっている。実行が失敗すると一時ファイルが消されないということがあるらしく、GCSのオブジェクトライフサイクルを併用して、bucketが肥大化しないように気を付ける必要があるそうだ。
また、外部パッケージを使いたい場合も一癖ある。ディフォルトでDataflowワーカーに入っていないパッケージを使いたい場合、--requirements_fileで外からパッケージの定義を渡す方法か、カスタムコンテナで外部パッケージがインストール済みのコンテナを用意する方法がある。