- 背景: BigQuery Editionsの登場およびOnDemandの価格変更
- 注意(Disclaimer)
- BigQuery Editionsの設定を行なう
- 脱線: BigQuery Editionsを選択して、OnDemandよりコストが上がってしまう場合
背景: BigQuery Editionsの登場およびOnDemandの価格変更
2023/03/29からBigQuery Editionsが販売開始され、2023/07/05からBigQueryのOnDemandの価格変更が適用されます(何もしないとコストが上がる)。
趣味プロジェクトでも多少BigQueryを利用していますが、OnDemandを利用しているので何もしないと約25%コストが上がってしまいます。しかし、うまいことBigQuery Editionsを利用すると逆にコストが下がる可能性もあります。BigQuery Editionsのプラン選択のような重要な設定は意図などがコードで分かる形でやりたいので、Terraformで設定してみたいと思います。
注意(Disclaimer)
今回のエントリは趣味プロジェクトでの気楽な設定をやってみたエントリなので、業務で設定する場合はもっと入念に検証などを行なった上でプラン選択や設定を行なうことをオススメします。
BigQuery Editionsの設定を行なう
providerのバージョンを上げる
BigQuery Editionは割と最近出た機能なので、providerのバージョンが古いと設定できません。案の定、私の手元の設定も古かったので、まずバージョンを上げるところから始めました。こんな感じで設定します。
terraform { required_providers { google = { source = "hashicorp/google" version = "4.64.0" } } ... }
設定後、terraform init -updateを実行すると、.terraform.lock.hcl内のバージョンが上がっていることも確認できました。
Reservationの作成およびAssignmentの設定
趣味プロジェクトのお気楽設定なので、 CommitmentやBaselineは特に設定しない前提で書いてます。
BigQuery EditionsではBigQuery Autoscalerが重要な役割を担っています。
- OnDemandでは2000スロット固定の元、処理したスキャン量に比例して課金がされます
- BigQuery Autoscalerでは処理に使ったスロット時間に比例して課金がされます
- 選択するEditionsによって使えるスロット数の上限が異なります
- Standardだと最大でも1600、EnterpriseやEnterprise Plusは上限はないが自分で上限を設定することもできる
BigQuery Editionsを使うにはReservation(予約)の作成およびAssignment(割り当て)の設定が必要です。Google Cloudの公式ドキュメントではReservationを管理する専用のプロジェクトを作ることが推奨されています。
Reservations リソース専用のプロジェクトを作成することをおすすめします。このプロジェクトは管理プロジェクトと呼ばれ、コミットメントの請求と管理を一元化します。このプロジェクトにわかりやすい名前を付けます(
bq-COMPANY_NAME-adminなど)。
しかし、今回は趣味プロジェクトのお気楽設定のため、Reservationを管理するプロジェクトと実際にクエリを走らせるプロジェクトは同一の設定で行ないましょう。「ReservationやAssignmentってそもそも何?」という場合は以下の書籍が分かりやすかったです。
![Google Cloudではじめる実践データエンジニアリング入門[業務で使えるデータ基盤構築]](https://m.media-amazon.com/images/I/51w8dXNHXbL._SL500_.jpg "Google Cloudではじめる実践データエンジニアリング入門[業務で使えるデータ基盤構築]")
Terraformでreservationの設定を行なうには、例えばこういった設定を書きます。
resource "google_bigquery_reservation" "reservation" { project = "my-project" # Reservationを管理するプロジェクトが別途あればそれを指定 name = "my-reservation" location = "US" # 実際にクエリを動かすlocationを指定してください。ずれていると意図せずOnDemandのままでクエリが動きそう slot_capacity = 0 # baseline slotsのこと。利用しない場合には0でよい edition = "ENTERPRISE" ignore_idle_slots = false # edition = "STANDARD" # ignore_idle_slots = true concurrency = 0 autoscale { max_slots = 100 } }
それぞれの設定の意味や試して分かったことを簡単にまとめてみます。
- Reservationは複数作成できます*1
- 例えば組織内に
STANDARDとENTERPRISEのReservationを2つ作り、プロジェクトによってAssignmentを変えるといったことも可能です - 例: Reservation A(
STANDARD)にプロジェクトBとC、Reservation X(ENTERPRISE)にプロジェクトYとZを割り当てる
- 例えば組織内に
slot_capacityはbaselineのことを指すようです- 定常的にスロットを利用する場合はbaselineを指定しておくほうがコストを抑えられたり、autoscaleのオーバーヘッドによらず安定してスロットを確保できるメリットがあります
- アドホックなクエリがたまに走ったり定期のバッチ処理が多少ある程度であれば、baselineは不要なこともあると思います
- 自分の趣味サービスのようなケースはこちら
- 利用したスロット数に比例した従量課金の体系となる
- baselineを採用したほうがよいかは管理リソースグラフでスロットの利用傾向を見ながら判断するとよいでしょう
- 自分の趣味サービスのようなケースはこちら
slot_capacityを0より大きい値に設定すると、一時間は再設定できないようなので注意しましょう- 実際にやってみたら
Cannot decrease slot_capacity within 1 hour from its last increased timeと怒られた
- 実際にやってみたら
editionでSTANDARD/ENTERPRISE/ENTERPRISE_PLUSのいずれかを選択しますSTANDARDではignore_idle_slots = falseの設定ができないなど、editionによって取れる値の組み合わせが違うようです*2STANDARD Reservation can not share idle slots, please set ignore_idle_slots to trueというエラーが返ってきた
autoscaleのmax_slotsは利用できる最大のスロット数となりますSTANDARDだと1600以上は設定できないはず- 意図せずコストが跳ね上がらないよう、何かしらは値を設定しておくのがよさそう
- 趣味プロジェクトなので今回は最小の100に設定してみてます
- 従来のOnDemandと同等のパフォーマンスが欲しいのであれば、2000を設定しておくとよさそう
- あるReservationに複数のプロジェクトを割り当てる場合はプロジェクト数に応じて多めにスロット数の上限を割り当てておくのがよさそう*3

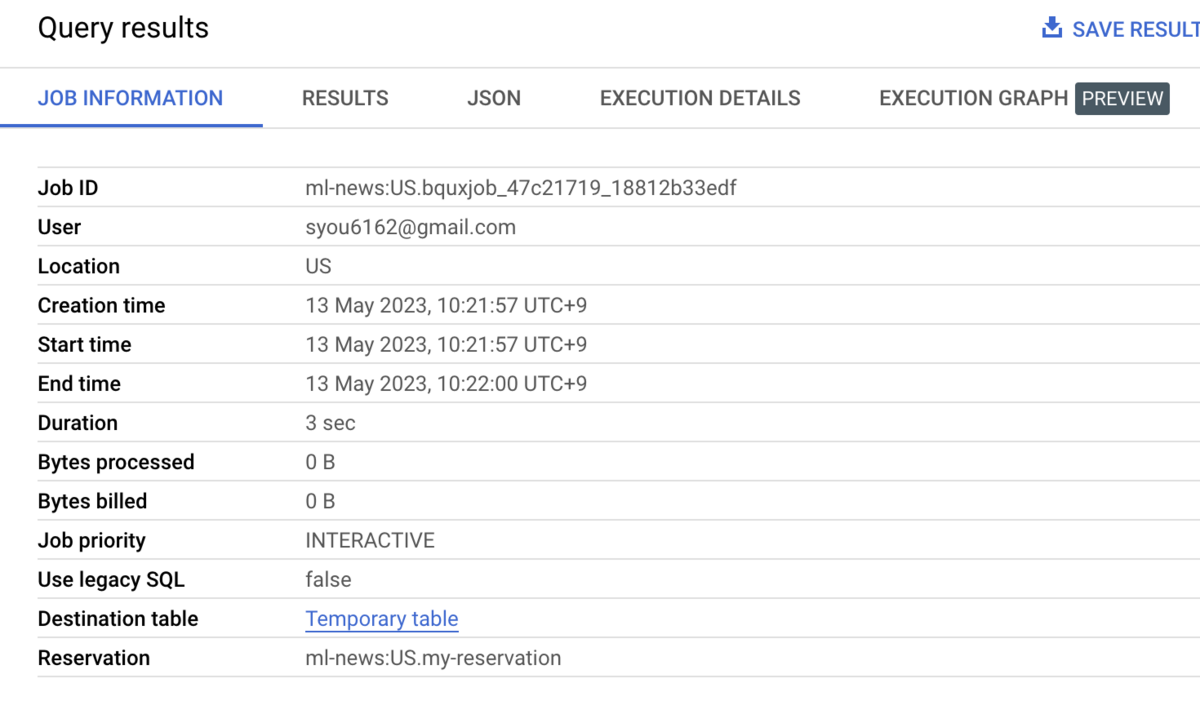
Reservationが作成できたので、これをベースにAssignmentも作成していきましょう。例えばこんな感じ。
resource "google_bigquery_reservation_assignment" "primary" { assignee = "projects/my-project" # Reservationを管理するプロジェクトではなく、実際にクエリを投げるプロジェクトを書く job_type = "QUERY" reservation = google_bigquery_reservation.reservation.id }
assigneeはReservationに対してどのプロジェクトを割り当てるかを記載します- プロジェクトだけではなく、フォルダーや組織を割り当てることもできます
- あるReservationに対して複数の割り当てを行なう場合には複数記述しましょう
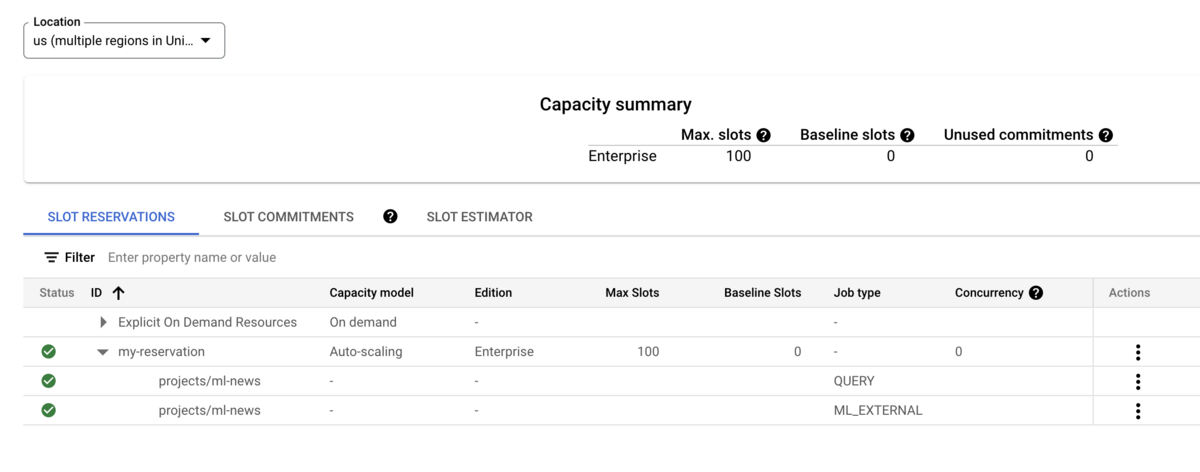
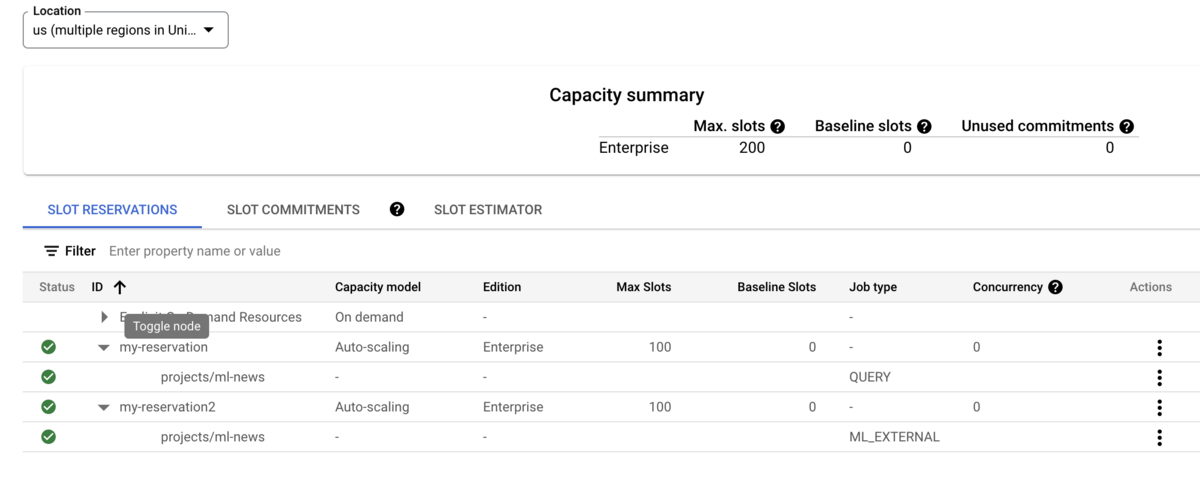
job_typeはQUERYやPIPELINEやML_EXTERNALなどを指定します- 詳細についてはこちらを参照してください
- 複数のReservationから同一のプロジェクトに対して異なる
job_typeを指定することもできますし、単一のReservationからから同一のプロジェクトに対して異なるjob_typeを指定することもできます- 例: ML関連は別途ワークロードを分けておきたい(slotを別途確保しておきたい)場合は
job_type = ML_EXTERNAL専用にReservationを作成しておく
- 例: ML関連は別途ワークロードを分けておきたい(slotを別途確保しておきたい)場合は
脱線: BigQuery Editionsを選択して、OnDemandよりコストが上がってしまう場合
長々とBigQuery Editionsの設定のことを書きましたが、自分の趣味プロジェクトでOnDemandからBigQuery Editionsに変えた場合、どれくらいコストが下がるかを試算してみました。「どれくらい浮くかな〜」と思って楽しみにしていましたが、結果は逆でコストが倍ほどかかる試算となりました。「えっ...?!」と思わず声を上げてしまい、何度も計算してみましたが、確かにコストが上がるケースはありそうということが分かりました。一例ではありますが、こういった場合です。
- 自分の趣味プロジェクト、スキャンしているデータ量が大きくない
- OnDemandは毎月 1 TB まで無料であり、自分の趣味プロジェクトはこの恩恵を割と受けている
- BigQuery EditionsではOnDemandのような無料枠がない
ということで、コストが増える形になっていました。弱小趣味サービスの場合はOnDemandのほうがお財布に優しいことはあるってことですね、勉強になりました。無料枠を大きく越えてBigQueryのOnDemandを使っている場合にはコストが下がる場合が多いと思いますが、ご自身の手でちゃんと試算してから適切なプラン選択を行なうようにしましょう。