背景 & Disclaimer
- 自分自身はこれまでBigQuery Scriptingをほぼ使っていませんでした
- BigQuery自体は3年くらいの利用歴
- SQL単発で済ませるのが苦しそうな場合は、Pythonなどのプログラミング言語 + ワークフローエンジンの組み合わせで戦っており、自分としては特に困っていなかった
- 社内で他の方が使うケースをぼちぼち見ることがある
- 自分は困っていなくても、社内のBigQueryユーザーでBigQuery Scriptingを使っていて困っている人がそれなりにいる
- 著者はそれなりのBigQueryユーザーがいる企業のデータ基盤の人間です
- さすがに「使ったことないので、分からないですねー」で済ませるわけにはいかなくなってきた
- 自分は困っていなくても、社内のBigQueryユーザーでBigQuery Scriptingを使っていて困っている人がそれなりにいる
- そもそもどんなユースケースで便利なのかすらも分かっていない状態なので、便利そうに思える場合をまとめてみることにしました
- というわけで、もっといい例などがあるかもしれないので、その辺は差し引いて読んでください...。むしろコメントなどで教えてください
- Syntaxの説明などはしないので、公式リファレンスを読んでください。便利そうな実例重視で書いてます
BigQuery Scriptingとは
BigQueryの普通のクエリは単一のSQLのステートメントです。1000行あろうが、WITH句のようなCTEがあったとしても単一のSQLです。BigQuery Scriptingは複数のSQLのステートメントの集合を一つのリクエストで実行できる機能です。
SELECT句のみからなる複数のSQLを扱っていると何がうれしいかピンときませんが、例えばこういった処理は単一のリクエストで処理できるとうれしい場合があります。
- SQLで中間テーブルA, B, Cを作る
- A, B, Cを
JOINしてテーブルDを作る- 例: 今日の分の要約統計量を作る
- テーブルDをテーブルEにマージする
- 例: 累積で結果を溜めているテーブルEに今日の分の統計量のDをマージする
- 不要になったテーブルA, B, Cを削除
単純にSQLを上から下に実行していくだけではなく、BigQuery Scriptingは以下のようなもっと高度な機能を提供しています。
- テーブルの作成などのDDL
WHILEやIFなどの制御構文が使える- 例:
INFORMATION_SCHEMAなどの結果を受け取って、ループで後続のSQLを実行する
- 例:
- 変数が扱える
- 動的にSQLを組み立てて(
EXECUTE IMMEDIATE)実行できますWHERE句の条件を制御構文を使ってガシガシ作っていく、など
- トランザクションが使えます
- まだプレビューの機能ではあり、制限は色々ある様子
単体で見ていてもイメージが分かないことも多いので、例を見ていきましょう。
BigQuery Scriptingの実例
例: 一時テーブルを使ってtoo many subqueries or query is too complexを回避する
BigQueryに限らずビューは便利ですが、多段のビューになるとResources exceeded during query execution: Not enough resources for query planning - too many subqueries or query is too complexというエラーでクエリが実行できないことがたまにあります。WITH句を多用していたり、ビューの多段が10個近くになってくるとこのエラーがよく発生することが多いです*2。
分析できないのは困るので、ビューのどこかをテーブル化して回避することが多いと思います。テーブル化は便利ではあるのですが中間テーブル自体は不要であり、集計後には消すこともセットで考えたいです。さもないとデータセットがゴミ屋敷になってしまいます...。しかし「何かの処理が終わった後にこのテーブルを消す」というのはそれなりに面倒なものです。Airflowのようなワークフローエンジンを使えば済みますが、SQLを動かしている分析チームにそういったワークフローエンジンをメンテナンスする工数がないということもあるでしょう。
そういった場合に便利なのがBigQuery Scriptingの機能の一つである一時テーブルです。CREATE TEMP TABLEを使ってテーブル化すると
- テーブルを元に後段のクエリを書けるため、
too many subqueries or query is too complexのエラーを回避できる - 一時テーブルであるため、BigQueryが削除をやってくれる
というメリットがあります。
普通のSQLっぽいので、BigQuery Scriptingであることを見逃してしまいがちですが、これもBigQuery Scriptingで使える機能の一つです。ほぼ同じですが、一時的なUDF(ユーザー定義関数)を作る場合にもCREATE TEMP FUNCTIONが使えて、これもBigQuery Scriptingでできることの一つです。
例: 縦持ちのデータを横持ちに変換(データを元にSQLの自動生成)
SQL単独で変換するのが面倒なケースとしては縦持ち <=> 横持ちの変換があります。縦持ちのデータの例として、bigquery-public-data.samples.natalityを見てみましょう。
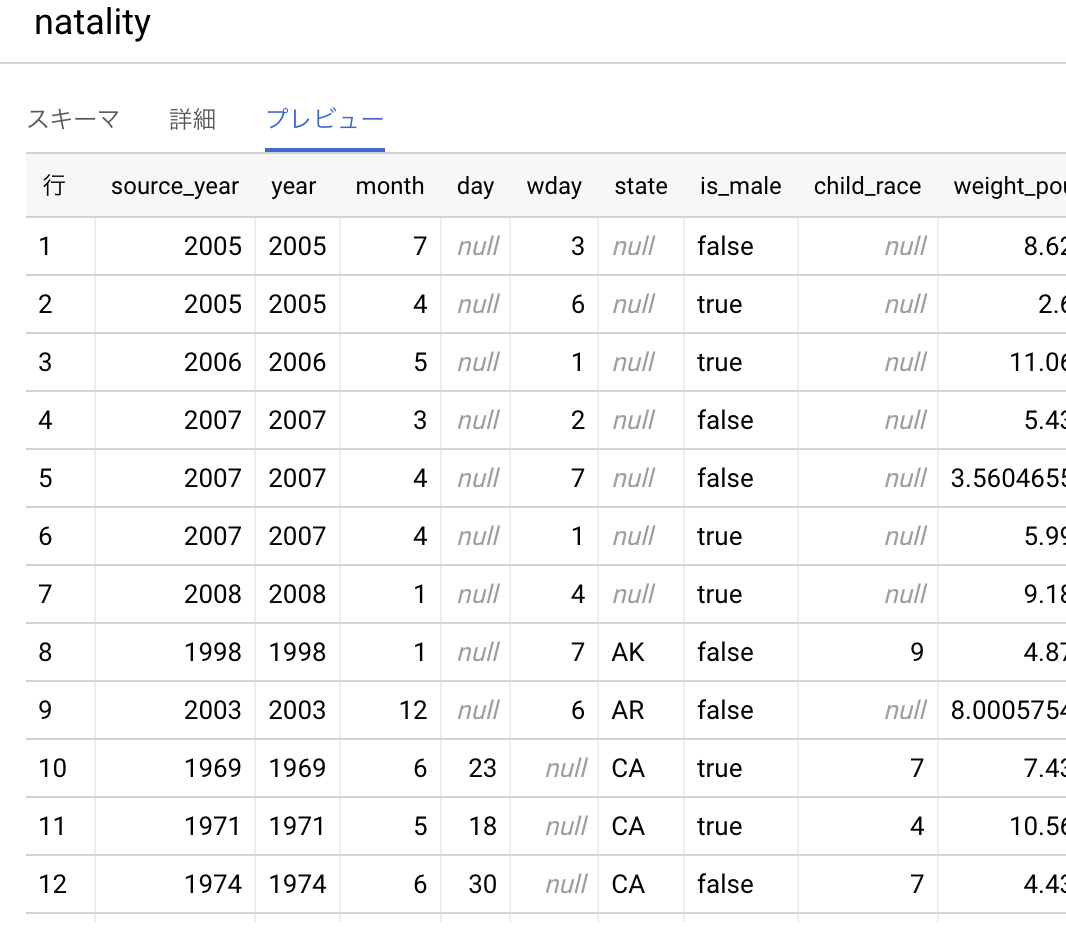
この縦持ちのデータを集計 & 横持ちにして、州毎の出生数の推移を出してみましょう。州を列に取り、横持ちで取ることを考えます。SQLとしては以下のような形でしょうか。アメリカの州は数十個あるのでSELECT句を手で書いていると発狂してしまいそうです...。
SELECT source_year, SUM(IF(state = "AK", 1, 0)) AS AK, SUM(IF(state = "AR", 1, 0)) AS AR, ... FROM `bigquery-public-data.samples.natality` GROUP BY source_year ORDER BY source_year
発狂しないためにもSQLを自動で生成することを考えましょう。これはいかにもBigQuery Scriptingの出番ですね。以下のようにSQLを組み立てました。WHILEループを回してもよかったのですが、副作用があると嫌なのでmapしてからreduceでまとめる形で書いています。
DECLARE states_sql STRING; CREATE TEMP TABLE states_sql_str AS WITH states AS ( SELECT state FROM `bigquery-public-data.samples.natality` WHERE state IS NOT NULL -- NULLのケースも扱う必要があるが、今回の説明の本質とは関係ないので、一旦除外する GROUP BY state ORDER BY state ), state_sql AS ( SELECT "const" AS const_col, -- STRING_AGGで一行にするために、定数のカラムを入れる "SUM(IF(state = \"" || state || "\", 1, 0)) AS state_" || state || "," AS sql -- SQLのキーワードと被るstateがあるので、適当にprefixを付ける FROM states ) SELECT STRING_AGG(sql, "\n") AS sql FROM state_sql GROUP BY const_col; SET states_sql = (SELECT sql FROM states_sql_str LIMIT 1); EXECUTE IMMEDIATE FORMAT(""" CREATE OR REPLACE TABLE my-project.my_dataset.us_natality AS SELECT source_year, %s FROM `bigquery-public-data.samples.natality` GROUP BY source_year ORDER BY source_year """, states_sql);
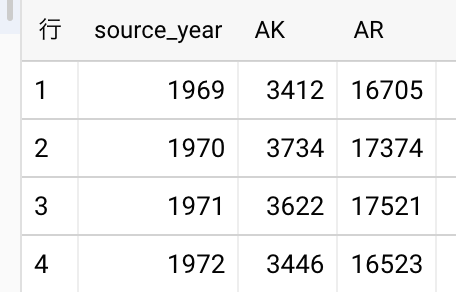
州の数分だけカラムに対応するSQLが自動生成されて、横持ちした結果は以下のように横長になります。BigQuery Scriptingで自動的にやっているので、列の数がもっと増えても対応できそうですね。

...と頑張ってはみたものの、横持ちへの変換はスプレッドシートやBIツールで変換したほうが適切な場合も多いので、使う場面は考えたほうがよさそうです。また、最近BigQueryの関数としてPIVOTとUNPIVOT関数が利用できるようになっており、自分で縦横の変換をするケースは減ってきそうですね*3。
以下のエントリでは列として横で持っているデータをSTRUCTの形で縦持ちにSQLの動的生成で変換する方法が紹介されており、参考になります。
発展系としてはこういうこともできます。
例: 複数のテーブルを一括でコピー
複数のテーブルを別のプロジェクトやデータセットにコピーすることを考えましょう(複数テーブルの一括削除などもほぼ同様にできます)。私はエンジニアなので、bqコマンド+xargsなどで適当にシェルスクリプトを書きますが、エンジニアでない方にこれらのツールを入れてもらうのはハードルが高いケースが多いです。しかし、エンジニアではないもののSQLだけは書けるという方は思ったよりたくさんいます。
BigQueryでは、テーブルのコピーや削除などもSQLで可能です。各テーブルに対して、COPY TABLEのSQLを実行してやればよいので、ループで回してあげれば簡単に一括コピーできます。cpコマンドの感覚でいるとsrcとtargetの順番が違うので、そこは事故らないように注意しましょう。
DECLARE source_project STRING DEFAULT "my-project"; DECLARE source_dataset STRING DEFAULT "source_dataset"; DECLARE target_project STRING DEFAULT "my-project"; DECLARE target_dataset STRING DEFAULT "target_dataset"; DECLARE source_tables ARRAY<STRING> DEFAULT ["table_a", "table_b", "table_c"]; FOR table IN (SELECT table AS name FROM UNNEST(source_tables) AS table) DO EXECUTE IMMEDIATE FORMAT(""" CREATE OR REPLACE TABLE %s.%s.%s COPY %s.%s.%s """, target_project, target_dataset, table.name, source_project, source_dataset, table.name); END FOR;
source_tablesに相当するテーブルの一覧を自動的に出したい場合、INFORMATION_SCHEMA.TABLESが便利です。詳しくは以下を参照してください。
例: 不正なデータが入ってきた場合に処理を中止させる
SQLを書いていると、コードではなくデータが不正だった...ということは稀によくあると思います。自グループ以外の人にデータを提供するなど、データ品質を保証したい場合は素早く気付きたいものです。作ったデータに対してSQLで監視を入れるとかdbtのテストを入れるなどの方法もありますが、BigQuery Scriptingを使って手早く気付けるようにすることもできます。
BigQueryではASSET文とERROR関数がこの用途で使える機能です。ASSERT文はデータ全体を見た上でのテスト(例: UNIQUE制約、中央値や平均値が異常になっていないか)、ERROR関数は行単位でのテスト(例: 値域の異常がないか)という使い分けです。また、スケジュールクエリは失敗した場合にメールへの通知やpub/sub連携ができるので、簡単なデータの監視の仕組みを作ることもできます。
ASSERT ( (SELECT COUNT(*) FROM UNNEST([1, 2, 3, 4, 5, 6])) > 5 ) AS 'Table must contain more than 5 rows.';
SQLのデバッグをする際にこの辺りは役に立ちますね。詳しくは以下のリンクを参照してください。
例: レコードの要約統計量を使ってパーティショニングを効かせる
BigQueryは基本的にfull scanでクエリが走る & scan量に応じて従量課金*4です。Google Analyticsやサーバーのログなどイベント系のテーブルを操作する場合、何も考えずにクエリを書いてしまうと元々のテーブルが大きいこともあり、scan量が大きくなりがちです。1クエリで数TBなんてこともしばしばあります。
これを避けるには、BigQueryのテーブルに対してパーティショニングを設定する場合があります。WHERE event_timestamp >= "2022-03-01"などでscan量をぐっと減らせます。CURRENT_DATE()を指定することも多いですが、問題になるケースもあります。例えば
CURRENT_DATE()を元に1週間分のデータから分散を計算していた- テーブルの差分転送がたまに失敗する
- 差分転送が週末失敗したため、データ数がいつもの5 / 7になっており、意図せず分散*5のバラつきが大きくなってしまった
- 一致性が満たされにくくなってしまった
- 回避策としては、一ヶ月分のデータを見るなどもあるが、scan量が不要に増えてしまうため、可能ならば避けたい
などです。羃等性を考えてCURRENT_DATE()をなるべく使いたくないという場面もあるでしょう。CURRENT_DATE()を使わず、テーブル内の最新のevent_timestampから一週間以内のデータ、と条件を変更すれば問題を回避できそうに思えます。しかし、動的に条件の値が決まる場合は、BigQueryのパーティショニングが効きません(full scanが走ってしまう)。BigQuery Scriptingはこうした場合に有用です。DECLAREやSETなどで条件の元になる変数を用意し、それを元にWHERE句を組み立てると、無事にパーティショニングが効いてscan量を削減できます。詳しくは以下を参照してください。
例: 定期的にクエリ結果をGCSに出力する
社外の方とデータ連携をする際にGCSを使うケースがあるとします。BigQueryの生のテーブルは見せたくなくて、例えば
- 要約統計量に落としたものを提供する
- 個人情報に値するカラムを落とするかマスクして提供する
などが考えられるでしょう。これを毎回手動で実行していると面倒です。
- クエリを実行する
- クエリが終わるのを待つ
- Webの画面からぽちぽちとGCSにエクスポート
- 連携先へ連絡
...を毎月やっていると、年間だと十数時間くらいかけている工数を可能性があります。BigQuery Scriptingを使うと、クエリ結果をGCSに出力することができ、これをスケジュールクエリに登録しておけば自動的に社外の方へのデータ連携が可能になります。日々のオペレーションは楽をして過ごしましょう。
EXPORT DATA OPTIONS( uri='gs://bucket/folder/*.csv', format='CSV', overwrite=true, header=true, field_delimiter=';') AS SELECT field1, field2 FROM mydataset.table1 ORDER BY field1 LIMIT 10
これはめちゃくちゃ簡単で、エンジニア工数なしでも対応できるケースも多そうですね。
例: スケジュールクエリでDDLを定期実行する
パーティションされたテーブルの使用が公式で推奨されているものの、特定時点のテーブルのスナップショットをmy_table_20220312のような日付別テーブルに保存しているチームは多いと思います。ある時点でのテーブルの状態が保存されているので、過去時点の分析や障害の調査に(その性質上、時々ではありますが)力を発揮します。ただ、通常の分析では日付別テーブルのうち最新のテーブルにのみ興味があることがほとんどだと思います。ユーザーが使いやすいようにするためには
SELECT * FROM my_table_20220312
というビューをmy_tableを用意する、などが考えられます。日付の部分は毎日変更する必要が出てきます。こうした変更(DDL)を定期的に行なうには、BigQuery Scripting + スケジュールクエリが便利です。例えば以下のクエリをスケジュールクエリで定期的に実行すれば、毎日最新のテーブルを参照するビューができあがります。
DECLARE target_date STRING; SET target_date = FORMAT_DATE('%Y%m%d', (DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY))); EXECUTE IMMEDIATE FORMAT(""" CREATE OR REPLACE VIEW my_dataset.my_table AS SELECT * FROM `my-project`.my_dataset.my_table_%s """, target_date);
...とは書いてみたものの、実際にこれを運用に乗せるのはオススメしません。理由としては
- スナップショットテーブルが存在しない場合がある
- データ転送に失敗した場合など
- そういったケースを無視すると、このビューを参照するクエリが常に失敗してしまう
- スナップショットテーブルが存在しない場合などのエッジケースをBigQuery Scriptingで担保しようとすると大変
- BigQuery Scriptingは便利ではあるものの、一般的なプログラミング言語と比べるとこの辺りはまだ辛みが多い
- この辺をちゃんとやるんだったら、ワークフローエンジンなどを使うほうが心配事は減る
などがあります。責任境界点としても、データ転送をするチームが日々のビュー作成まで行なうのが適切だと思います。DDLはあくまで「例の一つとしてこういうことができるよ」くらいに思っておいてもらうのがよさそうです。
まとめ
BigQuery Scriptingの便利と思われる利用例を紹介しました。かなり便利な例もたくさんありますが、特にEXECUTE IMMEDIATEのように動的にSQLを構築するものはバグが入りがちだったりするので、用法容量を守って使いましょう(PIVOT関数のように簡単にできる関数があるものは、なるべくそちらを使う)という感じかなと個人的には思いました。
![Google Cloudではじめる実践データエンジニアリング入門[業務で使えるデータ基盤構築]](https://m.media-amazon.com/images/I/51s2EB1vvoL._SL500_.jpg "Google Cloudではじめる実践データエンジニアリング入門[業務で使えるデータ基盤構築]")
")