Kubernetes上で動かしているバッチ処理の監視をCloud Monitoringで行なおうと思ったのですが、素朴にやるとちょっと困りました。一工夫したので、メモを残しておきます。
背景
- Webサービスの監視と同様にバッチ処理についても監視は必要です
- MackerelなどのSaaSを使うと、バッチ処理についても簡単に監視できます
- ただ、仕事のチームではMackerelを今は使っていません。GCPを使っているので、Cloud Monitoringでやるかなーという感じ
- メトリックやダッシュボードに関してはCloud Monitoringもよくできてる
- Mackerelを導入してもよいのですが、運用のことも考えると無闇にツールを増やしたくないので、Cloud Monitoringでやってみる
Cloud Monitoringで素朴にバッチ監視を行なう
GKEでバッチ処理を動かしている場合、エラーログはCloud Loggingに流れると思います。Cloud Loggingではログを数値に丸めるカウンタ指標というのを作ることができます。監視を行なう場合、カウンタ指標をベースにやっていくことになると思います。
Terraformで書いてみると、例えばこんな感じ。ログレベルなどは適当に調整しましょう。
resource "google_logging_metric" "batch_error_count" { name = "gke-batch-error-count" description = "GKE上のバッチで起こったエラー数" filter = local.filter metric_descriptor { display_name = "Batch Error Count" metric_kind = "DELTA" unit = "1" value_type = "INT64" } } locals { filter = <<-EOT resource.type="k8s_container" resource.labels.cluster_name="ml-news" resource.labels.namespace_name!="argo" severity=ERROR resource.labels.namespace_name!="kube-system" NOT textPayload: "level=info" EOT }
このカウンタ指標を元にアラートポリシーで監視を入れれば、素朴なバッチ監視は完成です。アラートポリシーから発報されたインシデントをメールで知らせたり、インシデントから該当時刻のログをさっと見ることができて便利です。
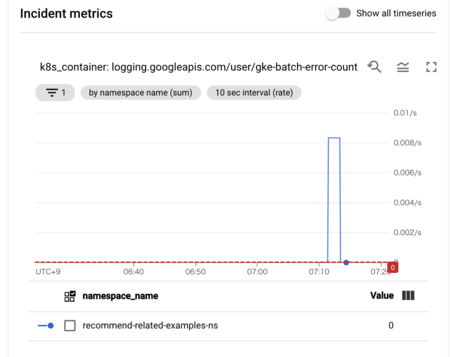
これだと困る...!
この方法でバッチ処理の監視をしばらく運用してみると、割と困ることに気付きました。先程のカウンタ指標だと、エラー行数をベースにしているため、インシデントは正常に作成(open)されます。しかし、バッチ処理がエラーで終了した後は、エラー行数が0行になってしまうため、インシデントはすぐに終了(close)してしまいます。これだと以下の点が困ります。
- エラーが現在も起きているのか分からない
- 一回失敗して次は成功したのか、失敗し続けているのか知りたい
- 最後の実行がエラーで終了していたのなら、インシデントはcloseせず、openのままであって欲しい
- エラーの継続時間が分からない
- インシデントがopenしてから、次のバッチが成功して初めてインシデントがcloseしたとしたい
- こうなっているとエラーの継続時間が計測できる
- インシデントが複数発生してアノテーションすべき場所がバラけてしまう
- 1時間毎にバッチを起動していて、5時間バッチが失敗し続けている場合、5つのインシデントが作成されます
- Cloud Monitoringでは対応履歴などをアノテーションとして残すことができますが、複数インシデントが発生すると、どのインシデントに記録を残していけばいいか分かりません
- 記録がバラけても困る
次のバッチが成功するまでインシデントが閉じないようにする
困り事を解決するには、インシデントがopenしたら次のバッチが成功するまで閉じないようにする仕組みが必要です。状態を自前で管理するのは面倒なので、kubectl get podsの結果から、最新の結果がFailedで終わっているnamespaceの一覧を出力するスクリプトを用意しました(各ジョブはnamespace毎に別れていることを仮定)。出力の形式をcsvにして、![]() id:mattnさん作のqqに食わせて
id:mattnさん作のqqに食わせてFailedなnamespaceのみstderrに吐くようにしています。
#!/bin/sh set -eu -o pipefail SQL=$(cat << EOS WITH tmp AS ( SELECT *, ROW_NUMBER() OVER (PARTITION BY namespace ORDER BY timestamp desc) AS rank FROM stdin ) SELECT namespace FROM tmp WHERE rank = 1 AND status = "Failed" EOS ) COLUMNS_FORMAT="namespace:metadata.namespace, timestamp:metadata.creationTimestamp, status:status.phase" for ns in $(kubectl get pods --all-namespaces -o=custom-columns="${COLUMNS_FORMAT}" | qq -q "${SQL}"); do echo "- namespace = ${ns}のバッチでエラーが発生しています" 1>&2 done
このスクリプトをcronで毎分回します。stderrに吐かれたものはCloud Loggingではエラー扱いになるので、仮にバッチがエラーでこけた場合は次のバッチが成功するまでstderrにログが吐かれます。このエラー行数をカスタム指標にして監視をすれば所望のものが完成です。
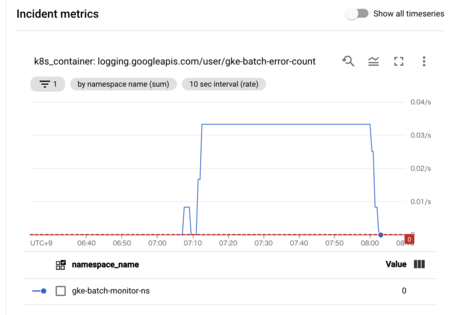
監視するためのアラートポリシー(terraform)はこんな感じ。
resource "google_monitoring_alert_policy" "gke_batch_monitor_alert_policy" { display_name = "GKE上のバッチが落ちています" combiner = "OR" conditions { display_name = "Batch Error Count by label.namespace_name [SUM]" condition_threshold { comparison = "COMPARISON_GT" duration = "0s" filter = "metric.type=\"logging.googleapis.com/user/gke-batch-error-count\" resource.type=\"k8s_container\"" threshold_value = 0 aggregations { alignment_period = "120s" cross_series_reducer = "REDUCE_SUM" group_by_fields = [ "resource.label.namespace_name", ] per_series_aligner = "ALIGN_RATE" } trigger { count = 1 percent = 0 } } } notification_channels = [ "projects/my-project/notificationChannels/1234567890", ] documentation { content = local.content mime_type = "text/markdown" } } locals { content = <<-EOT 即時対応は必要ありません。インシデント発生近くのログを見に行きましょう。 バッチ処理を再実行する方法: - `argo server -n argo`で手元からargoに接続しましょう - http://localhost:2746/cron-workflows/ から失敗したバッチを選択して再実行しましょう EOT }
Cloud Monitoringでバッチ監視をしている方、自分はこうやっているよというのがあったら是非教えてください!