- 背景
- 課題: Workflow内で複数のジョブが走る場合に監視漏れが発生する
- 解決方法: Workflow単位で成否を判断し、Cloud Monitoringに成否をメトリックとして投稿する
- Appendix
背景
- Cloud Monitoringでバッチ処理の監視をしようと思うと、思った通りの監視ができないことがある
- こういうケース
- バッチ処理の個々の失敗はある程度許容できる
- 最後に実施したバッチが通っていればOK
- 例: 古いテーブルの削除。たまに失敗しても、次回削除されれば特に問題ない
- バッチ処理の失敗自体はCloud Monitoringで検知できるが、「最終的なバッチの成否」が知りたい
- Workflowの実行はArgo Workflowsを使っている
- バッチ処理の個々の失敗はある程度許容できる
- こういうケース
- この問題を解決すべく、簡単なシェルスクリプトを以前書いた
kubectl get pods --all-namespacesの出力から判定- 同一namespace内で最後に完了したpodの成否を見る
- Cloud Monitoringで監視をするために失敗したnamespaceをSTDERRに出力しているが、無駄にログが汚れてしまうという問題もあった
課題: Workflow内で複数のジョブが走る場合に監視漏れが発生する
直列で動くような単純なWorkflowについては特に問題なく運用できていた。しかし、並列で複数のジョブが走る場合(Argoの場合はstepsを使うケースなど)、Workflowの失敗の検知漏れが起きる問題があった。
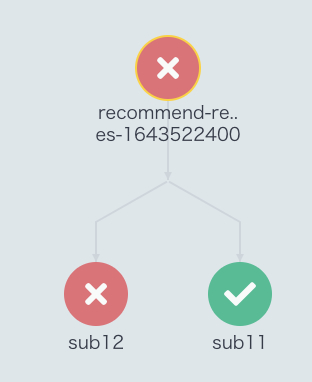
具体例で説明する。以下のようなsub11とsub12が並列で動くWorkflowを考える。
sub11は比較的複雑な計算をしており、ある程度時間が経ってから正常に終了したsub12は簡単な計算をしているだけだが、権限付与漏れですぐに異常終了した
この場合、「同一namespace内で最後に完了したpodの成否を見る」というやり方ではsub11の成否を見るので、Workflowは成功したと見做される。しかし、系としては失敗しているので、これは検知漏れとなり、これは問題である。
解決方法: Workflow単位で成否を判断し、Cloud Monitoringに成否をメトリックとして投稿する
解決方法は簡単で、namespace内で判断するのではなく、Workflowの単位で成否を判断すればよい。Argo WorkflowsはCLIツールからWorkflowの状態を見れるため、その出力を適宜加工してあげればよい。具体的にはこんな感じ。
#!/bin/sh set -eu -o pipefail WORKFLOW=$(argo list -A -o json) # 成功したnamespaceをメトリックとして投稿 echo "${WORKFLOW}" \ | jq -r '. | group_by(.metadata.namespace) | map(max_by(.metadata.creationTimestamp)) | .[] | select(.metadata.labels."workflows.argoproj.io/phase" != "Error" and .metadata.labels."workflows.argoproj.io/phase" != "Failed") | .metadata.namespace | {"labels": {"namespace_name": .}, "value": 0}' \ | jq -c -M \ | cloud_monitoring_metrics_throw --project my-project --metricName gke_batch_error_count # 失敗したnamespaceをメトリックとして投稿 echo "${WORKFLOW}" \ | jq -r '. | group_by(.metadata.namespace) | map(max_by(.metadata.creationTimestamp)) | .[] | select(.metadata.labels."workflows.argoproj.io/phase" == "Error" or .metadata.labels."workflows.argoproj.io/phase" == "Failed") | .metadata.namespace | {"labels": {"namespace_name": .}, "value": 1}' \ | jq -c -M \ | cloud_monitoring_metrics_throw --project my-project --metricName gke_batch_error_count
jq芸感があるが
.metadata.namespaceでグルーピングして、ジョブを投げた時間が最新(.metadata.creationTimestamp)のものを取得- 現在の実行フェイズ(
.metadata.labels."workflows.argoproj.io/phase")がErrorかFailedな場合のみフィルタ - 出力をjsonl形式に加工
という感じ*1。jsonl形式になればメトリック投稿は前回用意したcloud_monitoring_metrics_throwに任せればよく、投稿するためのjsonデータへの加工だけをどうすれば考えればよい。簡単なツールの組み合わせでいける点が個人的に気に入っている。
できあがりとしてはこんな感じ。どの時間にどのWorkflowが失敗したか簡単に分かるし、これまでのツールと違って監視漏れがなくなった。

Appendix
この監視を実際に設定するために必要な設定ファイルについても書いておく。
GKEのサービスアカウントへの権限付与
workflowsのlistを叩くのに必要な権限を付与する必要がある。k8sの設定に追加する。
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: gke-batch-monitor-argo-cluster-role rules: - apiGroups: - "" resources: - pods verbs: - list - apiGroups: - argoproj.io resources: - workflows verbs: - list
監視用のDockerfile
cloud_monitoring_metrics_throwとargoという2つのコマンドラインツールが入ったイメージを作る。
FROM golang:1.17-alpine AS builder RUN apk add --no-cache make git build-base RUN go install github.com/syou6162/cloud_monitoring_metrics_throw@latest FROM alpine:3.14.0 RUN apk add --no-cache jq curl \ && curl -sLO https://github.com/argoproj/argo-workflows/releases/download/v3.2.7/argo-linux-amd64.gz \ && gunzip argo-linux-amd64.gz \ && chmod +x argo-linux-amd64 \ && mv ./argo-linux-amd64 /usr/local/bin/argo ENV APP_PATH="/app" WORKDIR ${APP_PATH} COPY --from=builder /go/bin/cloud_monitoring_metrics_throw /usr/local/bin/ COPY monitor ${APP_PATH}/
Cloud MonitoringのアラートポリシーのTerraformの設定
投稿したメトリックを元に監視の設定をする必要がある。Terraformで設定しておくのが簡単。
resource "google_monitoring_metric_descriptor" "gke_batch_monitor_metric_descriptor" { description = "GKE上でバッチのエラーが起きているか" display_name = "gke-batch-error-count" type = "custom.googleapis.com/gke_batch_error_count" metric_kind = "GAUGE" value_type = "INT64" labels { key = "namespace_name" value_type = "STRING" description = "バッチが動いているk8s上のnamespace" } } resource "google_monitoring_alert_policy" "gke_batch_monitor_alert_policy" { display_name = "GKE上のバッチが落ちています" combiner = "OR" conditions { display_name = "Argo上のバッチが失敗" condition_threshold { comparison = "COMPARISON_GT" duration = "0s" filter = "metric.type=\"custom.googleapis.com/gke_batch_error_count\" resource.type=\"global\"" threshold_value = 0 aggregations { alignment_period = "120s" cross_series_reducer = "REDUCE_SUM" group_by_fields = [ "metric.namespace_name", ] per_series_aligner = "ALIGN_MEAN" } trigger { count = 1 percent = 0 } } } notification_channels = [ "projects/my-project/notificationChannels/123456789", ] documentation { content = local.content mime_type = "text/markdown" } } locals { content = <<-EOT バッチが落ちてます。インシデント発生近くの[ログ](https://console.cloud.google.com/logs/query;query=severity%3DERROR%0Aresource.type%3D%22k8s_container%22%0Aresource.labels.namespace_name!%3D%22argo%22%0Aresource.labels.container_name%3D%22main%22?project=${"$"}{project})を見に行きましょう。 EOT }

*1:失敗した場合のみメトリック投稿すればいいかと思ったが、Cloud Monitoringのメトリックが補完してしまい分かりにくいかったため、明示的に成功した場合もメトリックとして投稿するようにした