背景: データ品質を可視化したい
運用しているDWHでデータ品質にまつわる問題で苦労したことがない人は少ないと思います。Analytics Engineerやデータエンジニアであれば「このテーブル、XXカラムに重複があるんだけど...」「この列の値、割合が入るんだから、マイナスとか1越えるとかおかしくない?」といった問い合わせを受けた経験が多いでしょう。
今回は上記のような完全性(Completeness) / 一意性 (Uniqueness) / 妥当性 (Validity)といったデータの正確性に関わるデータ品質の可視化をスコープにします。データ品質に限らない話ですが、こういった改善を行なうには「現状(AsIs)がどうなっているかを把握した上で、理想(ToBe)とのギャップがどれくらいあるか」を考えるのが重要です。ギャップを埋めていくには、現状のデータ品質がどうなっているかを可視化するのがよい一手になります。
実装: elementaryを使って、正確性のデータ指標を可視化する
DWHの構築にdbtを利用している場合、elementaryを使うとデータ品質の可視化がやりやすいです。以前にも可用性の文脈で可視化の事例を取り上げていました。
今回も同じようにelementaryを使って、正確性のデータ指標を可視化していきましょう。dbtを使っている場合、正確性はテーブルまたはカラムのtestとして実装されることが多いでしょう。elementaryの成果物の一つにdbt_testsというテーブルがあり、これを使うと指標の可視化が簡単にできます。実際に可視化を行なうためのSQLが以下になります。
select coalesce(dbt_models.database_name, dbt_sources.database_name) as project_name, coalesce(dbt_models.schema_name, dbt_sources.schema_name) as dataset_name, coalesce(dbt_models.unique_id, dbt_sources.unique_id) as model_name, dbt_tests.short_name as test_short_name, dbt_tests.test_column_name, dbt_tests.type as test_type, case when dbt_tests.short_name in ( "unique_combination_of_columns" -- https://github.com/dbt-labs/dbt-utils/blob/main/macros/generic_tests/unique_combination_of_columns.sql ) then "uniqueness" when dbt_tests.short_name in ( "schema_changes", -- https://docs.elementary-data.com/data-tests/schema-tests/schema-changes -- 独自実装のテストがあればこの辺に追加していく ) then "validity" when dbt_tests.quality_dimension is not null then dbt_tests.quality_dimension else "未分類" end as quality_dimension, dbt_tests.original_path, from `my-project.my_elementary.dbt_tests` as dbt_tests left outer join -- dbt_tests.type = singularは複数のmodelと紐付くので、それらを拾うためにleft outer joinにしている `my-project.my_elementary.dbt_models` as dbt_models on dbt_tests.parent_model_unique_id = dbt_models.unique_id left outer join -- dbt_tests.type = singularは複数のsourceと紐付くので、それらを拾うためにleft outer joinにしている `my-project.my_elementary.dbt_sources` as dbt_sources on dbt_tests.parent_model_unique_id = dbt_sources.unique_id
工夫点としては、以下があります。
- dbtのテストはテーブルもしくはカラムに対して行なわれることがほとんどなので、その2つのケースをケアできるようにしています
- さらにテストの対象はmodel(テーブルやビューなどの成果物)あるいはsource(データソース)があるので、それらの情報を
joinして補完して出せるようにしています- 補完する情報としては、データセット名やテーブル名など
- 各テストに対する正確性の指標の分類(
quality_dimension)はelementaryが概ねやってくれますが、dbtの基本的なテストしかカバーされていないことが多いので、dbt-utilsや独自実装のテストについてはcase whenで丁寧に分類していきます- どのテストがどの指標の分類されるかは実装を見るのがよいです
実例: ダミーデータを使った可視化
SQLだけ見ても、どういったことができるかイメージが湧かないと思うので、サンプルデータを元に可視化してみました。例えば、データセット毎にそれぞれの正確性の指標がどれくらい実装されているかを可視化してみましょう。
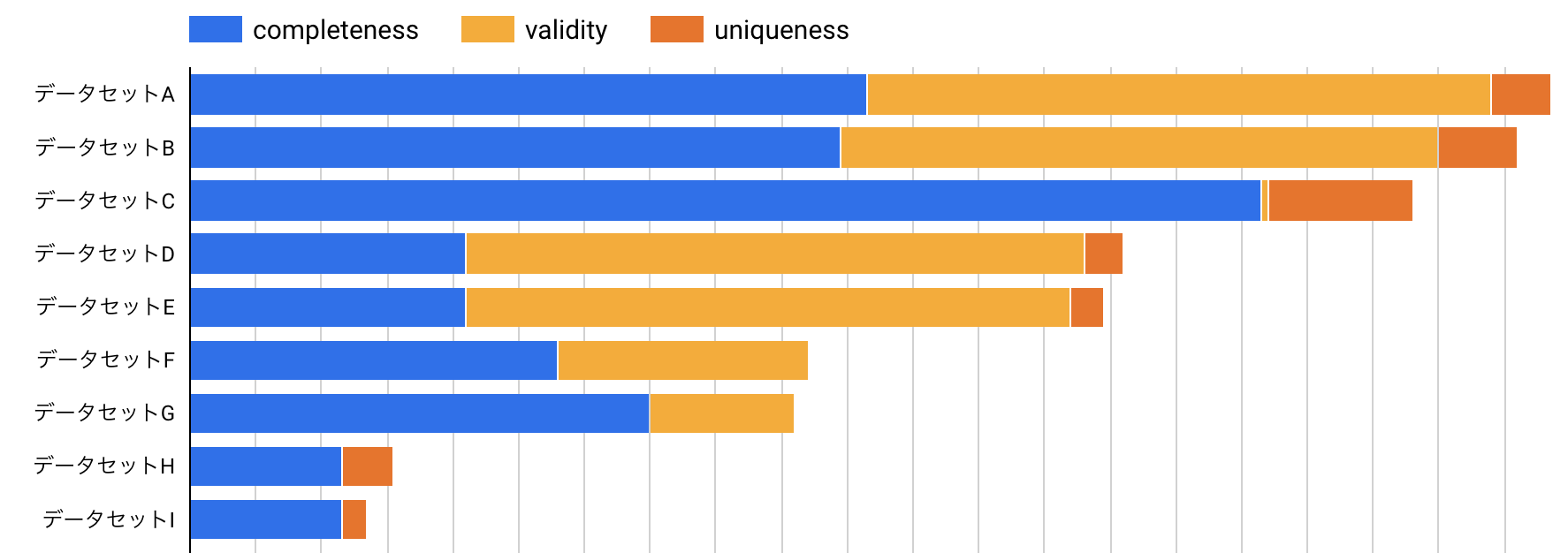
これはあくまでダミーデータですが、それでも例えば「データセットA / B / Cは特にテストが多いが、データセットCはvalidity(妥当性)に関するテストが圧倒的に少ない」といったことが分かります。今回の可視化ではデータセットを軸に可視化していますが、以下のようなことをやってみるとさらに面白い事実が見えてくるかもしれません。
tagを使ってレイヤリングを軸に可視化してみるtagはdbt_modelsに情報として含まれていますdbt_modelsにはファイルパスなども含まれているので、切り口は色々工夫できます
- テストの絶対数ではなく、1モデルあたりの平均テスト数を出してみる
- 社内で複数のデータプロダクトがある場合、データプロダクト間の品質の差異を見てみる
まとめ
今回はデータの正確性に関わるデータ品質の指標の可視化をelementaryを使って実装しました。30行くらいのSQLなので簡単に実装できる割には色々な示唆が得られることが多いので、是非試してみてください。
なお、データ品質の指標を目標にしてしまうと、ハックされてダメになってしまうことが多い(いわゆるキャンベルの法則)ので、可視化は現状の把握に留めて、そもそもどのレイヤーでどういったテストをすべきかといったことをチーム内で検討し、ギャップを縮めていけているかの把握などに使うようにするのがいいですね。