前提: これは何?
- dbtを使ったデータプロダクトを作っている社内のチームメンバー向けに書いた勉強会用のドキュメントです
- 社外に公開できるように少し抽象化して書いてます
- DWHに限らずdbtを使ったデータプロダクトで生かせる話ですが、分かりやすさのためにDWHを題材にしています
3行まとめ
- elementaryはdbtを利用しているデータパイプラインに対してData Observabilityを強化するツールであり、付属のリッチなレポートやSlachへのアラート通知が便利です
- しかし、実はelementaryが内部で生成している成果物はDWHの改善に役に立つものがたくさんあります
- 本エントリではelementaryの成果物や役に立つ実例を多めに紹介します
- 前提: これは何?
- 3行まとめ
- 背景: DWHとデータ品質
- elementaryでData Observabilityを加速させる
- elementaryが生成する成果物をDWH改善に生かす
- まとめ
背景: DWHとデータ品質
- DWHを作る際に、データ量の増加 / 元になるデータの種類の増加などにより、処理も複雑になったり、品質に問題を抱えることも多くなっています
- 一方で、ビジネスにおけるデータの重要性は高まるばかり
- 品質が低いことにより、機会損失が起きたり、DWHに依存するシステムへの障害に繋がる場合もある
- 品質は高めたいが、複雑なシステムを複雑なまま理解 / 運用するのは大変...
- (データの文脈に限らず)複雑なシステムの理解や信頼性を高めるなどの文脈でObservabilityが注目されている
Observability / Data Observabilityについて
- オブザーバビリティ(可観測性)とは|定義、意味、組織にもたらすメリット | Splunk
- 元々は分散システムの文脈、最近ではSRE界隈などでよく見かける
オブザーバビリティ(可観測性)とは、システムの出力を調査することによって内部の状態を測定する能力を指します。出力からの情報すなわちセンサーデータのみを使用して現在の状態を推定できるシステムは「オブザーバビリティがある」とみなされます。 Observabilityと英語では表記し、Observe(観察する)とAbility(能力)を組み合わせた意味の単語です。この言葉は最近の流行語ではなく、制御理論(自己調整システムについて説明し理解するための理論)に関連して数十年前に提唱された用語に由来します。ただし今日では、分散型ITシステムのパフォーマンス向上の文脈でよく使用されます。この場合のオブザーバビリティは、メトリクス、ログ、トレースの3種類のテレメトリデータを使用して分散システムを詳細に可視化し、さまざまな問題の根本原因の究明やシステムのパフォーマンス向上につなげることを意味します。
私自身はObservabilityの専門家ではないので、詳しいことを知りたい方は専門の書籍を読むことをお勧めします。

データエンジニアリングの文脈でもシステムやデータの状態について知りたいことはよくあります。いくつか例を挙げてみましょう。
- 複雑化したパイプライン
- 例: dbtのtransformの外側にあるデータソースの取り込み(
Data Ingestion) - 例: dbtの出力をCRMなど他システムに取り込む(
Data Activation) - 例: dbt内部での多段のレイヤリング
- 例: dbtを使っている場合でもmulti-projectになっている場合
- 例: dbtのtransformの外側にあるデータソースの取り込み(
- システムパフォーマンスの変化
- 例: 7時までに終わっていたバッチが終わらなくなったけど、どこが悪いんだ...いつから悪くなったんだ...
- データの型や統計量の変化
- 例: 1週間前からテーブル生成がうまくいってないことが分かったけど、データレイクのテーブルの型が変わったことが原因っぽい。いつから変わったんだ...
- 例: アナリストから指摘があって、このテーブルのNULLが三日前から急増していることが分かったけど、指摘がなくてもデータエンジニアが気付けるようにしたい
- incrementalに作っているテーブルはbackfillが面倒...
elementaryでData Observabilityを加速させる
- Elementary Data | dbt native data observability
Monitor data pipelines in minutes, in your dbt project- dbt nativeなデータのobservability(可観測性)を手助けしてくれるSaaS and/or OSS

elementaryの機能を利用する
事前設定
OSS版の設定についてはすでに書いてくださっている人がいるので、そちらを参考にしてください。割と簡単に始められる部類だと思います。
- dbt のデータモニタリングツール Elementary を使ってデータ品質管理を試してみた - Techtouch Developers Blog
- Elementaryで実現するデータオブザーバビリティの第一歩 #dbt - Qiita
- dbtのsource freshnessの実行結果をelementaryに収集させる - yasuhisa's blog
主要機能: Data Observability Dashboardの生成
こういう感じのダッシュボードを生成してくれるやつですね。時系列でテストが落ちた数やモデル毎の実行時間の推移などが分かります。OSSを利用している場合、edr send-reportでレポートを送ってくれます。レポートはS3やGCSに配置することができ、成果物は単純なhtmlなので、それを見るでも問題ないです。
主要機能: Slackへのアラート通知
こういうやつです。dbt CloudにもSlackへのアラート通知がありますが、全体で落ちたかどうかくらいしか通知してくれません。elementaryのslackへの通知は「どのテストが落ちたか」「何行くらいが影響を受けているか」などが分かりやすく表示されるので、結構好きです。
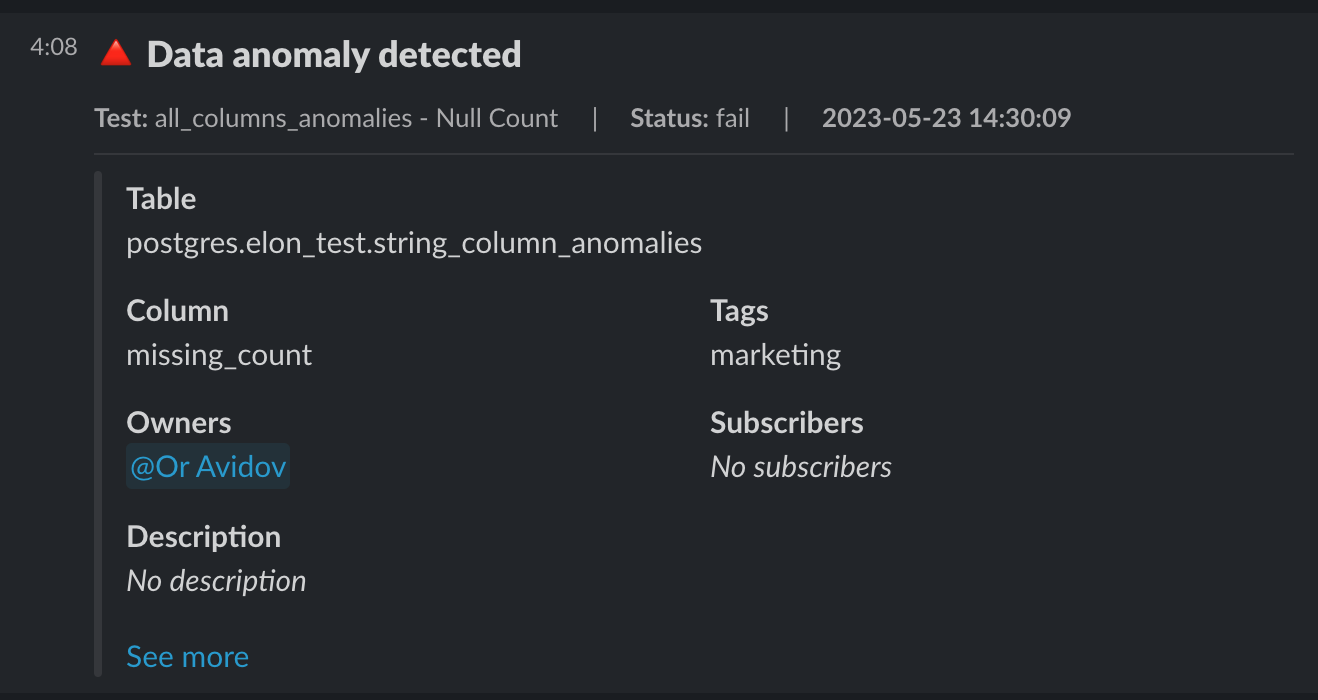
主要機能: スキーマ変更の検知
これは結構嬉しいです。「データソース側のシステム変更により、カラムの型が変わってしまっていつからかクエリが動かなくなった...」というのを経験したことがあるデータエンジニアの人は多いと思いますが、そういう事象を早めに検知する仕組みがelementaryには備わっています。
スキーマ変更の検知の方法は大きく分けて2つあります。
一つ目がスキーマ情報の変化を時系列で見る方法です。elementaryはdbtの実行後にon-end hookでデータソースや成果物のカラムの型などを保存していて、前回実行時と型の情報が異なる場合に検知してくれる方法です。時系列での型の比較をするだけなので、二つ目の方法と比べると比較的簡単に始めることができるのがメリットです。
二つ目がSchema changes from baselineで、yamlに書いているdata_typeとDBの型が異なる場合に検知する方法です。data_typeを記載しないといけない分手間はかかりますが、Data Contract的なことをやりたいのであれば、こちらのほうが理想的かなと個人的には思います。なお、data_typeを機械的に網羅したい場合、dbt-osmosisを利用すると一撃で埋めてくれるので、組み合わせて使うことをオススメします。
いずれの方法でもカラムの追加や削除の検知もサポートされています。
主要機能: データの値の異常検知
トランザクションデータのような履歴があるデータに対して、異常検知を行なうことができます。
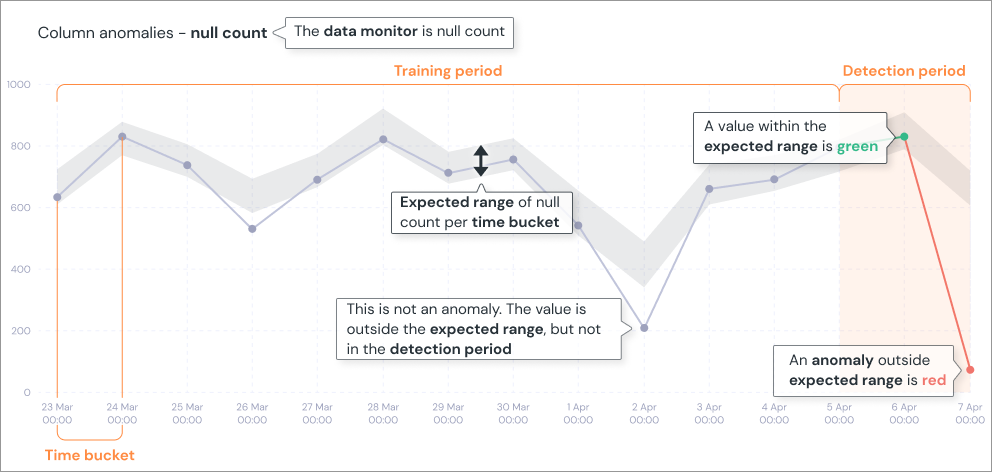
めちゃくちゃ高度な機械学習が入っているかというと、そんなことは別になく、Z-scoreのような非常に基礎的な統計量をベースにしています。とはいえ、季節性の考慮といった実用で必要なことはカバーしています。
元々、異常検知機能を開発したことがある人間なので異常検知にはうるさいのですが、異常検知機能を実用する際にはfalse positiveが多少あることは覚悟しましょう。例えば販促の施策などがあった際はfalse positiveでアラートが出やすいです。データを元にMLの運用をやっているMLエンジニアであれば有用な情報かもしれませんが、データエンジニアにとってはそのアラートが出ても特にやることが変わらないのであればノイズにしかなりません。
...と少しネガティブなことを書いてしまいましたが、値の平均値などはfalse positiveの問題があるものの、null_percent / max / zero_percentなどはデータエンジニアにとっても有用な場合があると思うので、取捨選択しながら利用してみるとよいかもしれません。
主要機能: dbt artifactsのアップロード
dbtを使っている場合、manifest.jsonなどの成果物はdbtのモデルといった有用なメタ情報を含んでいます。詳しくは本エントリの後半で触れますが、単純なmanifest.jsonだけだと使いにくい情報をelementaryが溶き解した上で成果物をアップロードしてくれるので、非常に利用しやすくなっています。
主要機能(SasS版のみ): リッチなリネージ機能
自分はOSS版しかまだ使ったことがないですが、SaaS版だとカラムレベルのリネージやBIも含めたリネージの取り込みをサポートしています。
後述しますが、BIも含めたリネージについては自前でexposureとして取り込むのをやっています。
elementaryが生成する成果物をDWH改善に生かす
さて、ここからがこのエントリの本番です。elementaryはData Observabilityを実現するため、様々なメタデータやログを出力します。elementaryをただただ利用するだけでも便利なのですが、elementaryが生成したデータ自体を使い込むと、もっとDWH改善に踏み込めます。どういうデータが生成されるかについて説明し、実例を交えながら解説します。
elementaryの成果物: dbt_run_results
- dbtの実行結果を蓄積する履歴テーブルです
- いつどういう{model, test, seed, snapshot}が実行され、どうなったか(status)が蓄積される
- これ単独だと、INFORMATION_SCHEMA.JOBSができることとほとんど変わらないように見える
- 単独だと割とそうだが、後述する
dbt_modelsやdbt_testsやdbt_sourcesなどと組み合わせると非常に強力 JOINして組み合わせるためのキーがunique_id
- 単独だと割とそうだが、後述する
- (当日用: 実際のテーブルを眺める)
実例: 可用性の可視化
- 全体あるいはテーブル毎の可用性はelementaryのGUIでも分かりますが、普段見たい指標はデータセット毎 / レイヤー毎 / タグ毎など自分の見たい切り口であることが多いでしょう
- テーブル毎の実行結果は
dbt_run_resultsに、自分の見たい切り口の情報はdbt_modelsに入っているので、それらを合わせることによって欲しいものが得られます。
elementaryの成果物: dbt_models
- dbtのmodel(table / view / ephemeralなど)に関するメタデータを保持しているテーブルです
- 情報量的には各種yamlファイル or
target/manifest.json(仕様はこちら)に記載されているものとほぼ同じです- しかし、yamlやjsonではなく、テーブルになっているということが重要です
- modelに関するメタデータにクエリでさっとアクセスできる、ということを意味します
jqやyq+ pythonなどが不要で、SQLだけで料理できる!- データパイプラインも簡潔に留めることができます
- カラム情報
database_name: プロジェクト名schema_name: データセット名tags: タグの配列が文字列で入っているので、使う際はバラす必要があるdepends_on_nodes: 依存(ref)しているモデルが配列として入っているdescription: 問題あるモデルの一覧を出したときに「このモデル、どういう目的のものだっけ」をさっと見れるoriginal_path: 問題あるモデルの一覧を出したときに「このモデルの定義調べたいな」をさっと調査できる
- (当日用: 実際のテーブルを眺める)
実例: データ管理を楽にするために、dbt管理しているテーブルかの判定に使う
- データガバナンスなどの文脈でBigQueryのコスト管理をしたい場面があると思います
- 例: テーブル生成に使うスキャン量 / スロット使用量、あるいはストレージ容量
- 対象のテーブルがdbt管理しているか / していないかでその後のアクションが変わってきます
- dbt管理であればdbtの運用者内で改善、監視の強化をする
- dbt管理外であれば利用者に連絡
INFORMATION_SCHEMA.JOBSのreferenced_tablesやINFORMATION_SCHEMA.TABLE_STORAGEのクエリ結果を使って上記のことを実現したい場合が多いですが、「dbt管理かどうか」をどうやって判断するかが鍵になりますdbt_modelsを使うと「dbt管理かどうか」を簡単に判定することができます
... WHERE referenced_tables.table_id IN (SELECT alias FROM `my-project.my_dataset.dbt_models`)
実例: modelの依存関係を再帰的に考慮して、安全にテーブルを撤退する
- データ基盤 / DWHの管理運用は工数が限られていることが多いため、新しいテーブルを作る以外にも、使われていないテーブルがいないか定期的に確認することが重要です
INFORMATION_SCHEMA.JOBSでテーブルの参照回数の多い / 少ないは分かりますが、対象のテーブルから派生しているテーブルが実は参照回数が多い、という場合もあり、テーブルの撤退判断は意外と難しいものですdbt_modelsのdepends_on_nodesにはテーブルの依存関係の情報が含まれているので、その情報を再帰的に辿ることにより、派生先のテーブルの参照回数も考慮することができますdbt_modelsのとWITH RECURSIVEの合わせ技です
- 10X社内では、これを元に作ったダッシュボードを見ながら古いバージョンのDWHの撤退をゴリゴリ進めています
実例: ダッシュボードとdbtの紐付けを行ない、データ品質のギャップの有無を把握する
- テーブルの撤退判断、障害があった際の影響調査などの場面でBIツールへの影響を考えないといけない場面は多いと思います
- dbt内の参照関係だけでは判断できない
- dbtにはexposureという仕組みがあり、ダッシュボードなどのBIの情報を依存関係に取り込むことができます
- 障害が発生し、あるテーブルに問題があった場合、
dbt_models/dbt_run_results/dbt_exposuresの情報を組み合わせることにより、影響があるステークホルダーにまとめて連絡をする、ということも容易にできますdbt_run_results: 障害のあったモデルの特定dbt_models: モデルの情報からBigQueryのテーブルを逆引きdbt_exposures:depends_on_nodesの情報があるので、障害があったモデルとの紐付けowner_emailの情報があるので、ステークホルダーへの連絡ができる
- また、exposureとdbtのモデルを紐付けると、データ品質のギャップの把握に使うこともできます
- 例えば、TableauであればWorkbookに対してタグを付与することができます
- dbtのモデルにもタグを付与することができます
- Tableau側には期待する品質のレベル(例: high)、dbtのモデル側には実際の可用性や正確性の運用状況を鑑みた品質のレベル(例: medium)を付与するようにします
- そうすると、期待値のギャップをSQLで集計することができ、どういったテーブルから品質を上げるべきか、ということを議論しやすくなります
- 参考: exposureを人手で管理するのは非常に苦行であるため、自動生成に寄せたほうがよいです
- 「ダッシュボードから参照されているテーブルはdbt管理されているものか」の判断に
dbt_modelsが役に立ちます - 各種BIツールを exposureとして取り込むための方法は以下のエントリを参照してください
- 「ダッシュボードから参照されているテーブルはdbt管理されているものか」の判断に
elementaryの成果物: dbt_tests
- dbtのモデルやデータソースにどのようなテストが実装されているかを保持しているテーブルです
- テストの実行結果が含まれているのは
dbt_run_resultsであることに注意です
- テストの実行結果が含まれているのは
カラム情報
short_name:not_nullやuniqueなどテストの短縮名が入る- より正確な名前が欲しい場合には
nameやaliasを参照するとよい
- より正確な名前が欲しい場合には
test_column_name: テーブルに対するテストではなく、カラムに関するテストの場合、テスト対象のカラム名が入るmodel_tags: モデルに付与されているタグ情報が配列(の文字列)として入るmodel_owners: テストが記載されているモデルのオーナー情報が入るparent_model_unique_id: テストが実装されているmodelやsourceへのjoinキーoriginal_path: テストが記載されているファイルパスquality_dimension:completeness/uniqueness/validitiyなど、どういった項目のテストかを大雑把に分類したカラム
(当日用: 実際のテーブルを眺める)
実例: データの正確性に関わるデータ品質の実装状況を可視化
- データ品質の中でもデータの正確性に関する指標は外せない話題だと思います
- 例:
完全性(Completeness)/一意性(Uniqueness)/妥当性(Validity)
- 例:
- データ品質の改善を行なうには「現状(AsIs)がどうなっているかを把握した上で、理想(ToBe)とのギャップがどれくらいあるか」を考えるのが重要
- ギャップを埋めていくには、現状のデータ品質がどうなっているかを可視化するのがよい一手になる
- 正確性に関するテストはdbtのテストで実装できることが多く、dbtのどのモデルやカラムにどういったテストが書かれているかという情報が
dbt_testsに含まれています- これをベースにちょっとしたクエリを書くと正確性に関する指標の可視化を簡単に行なうことができます
elementaryの成果物: dbt_invocations
dbt_run_resultsは一個一個のテーブルの生成にかかった時間などを保持してくれる成果物でした- 一方、
dbt_invocationsは各invocation_idがどういうジョブによって生成されたかの情報を保持しています - カラム情報
job_id: ジョブのidjob_run_id: ジョブのrun_id。dbtのバッチ全体での集計をやる場合はこれをkeyにしてGROUP BYするとよいrun_started_at/run_completed_at: runの開始時刻と終了時刻dbt_version: バージョン情報が含まれているので、バージョンアップ前後でパフォーマンスが劣化していないか、などを調査しやすいcause_category: スケジュール実行されたものか、手動実行されたものか、などが入っているpull_request_id: GitHubのCI経由でjobが実行された場合、Pull Requestのidが入る
実例: dbt cloudのジョブの実行時間の推移を可視化
- 各テーブルの生成にかかった時間の推移などはINFORMATION_SCHEMAなどで知ることができます
- 一方で「dbt全体のジョブ(正確にはrun)の実行時間の推移」がどうなっているかを知るのはINFORMATION_SCHEMAからだと案外難しいです
dbt_invocationsはdbtのjob_run_idなどの情報が入っているので、トータルで何時間処理にかかっているんだっけ、という情報を簡単に取得することができます
その他の成果物: dbt_exposures / dbt_sources
すでに登場しているものもありますが、その他使うことがありそうな成果物についてまとめておきます
dbt_exposures:
owner_email: BIツールなどのオーナー情報が分かります、利害関係者が誰かが分かっていると連携がスムーズですねurl: BIツールのURLを入れておくと便利ですdepends_on_nodes: BIツールが参照しているdbtのモデル情報を入れられますlabel: ダッシュボード名などを入ります
dbt_sources:
freshness_warn_after: freshnessの設定情報が分かります
まとめ
最近、自分が試しているelementaryを使ったDWH改善について、実例を豊富に取り上げながら紹介しました。BigQueryを使ってDWHを運用している場合はINFORMATION_SCHEMAのメタデータは欠かせないですが、dbtも使ってDWHを運用している場合はelementaryも同様に欠かせない存在になってきそうです。少なくとも自社ではデータ品質の可視化でゴリゴリに使い倒しています。
この他にも有用そうな使い方があればまた取り上げたいですし「うちではこういうことやってみてるよ!」というのがあれば是非教えて欲しいです。
")