3行まとめ
- dbtのジョブが失敗した際やテーブルの廃止検討の際に、BI上のどのダッシュボードで利用されている(データリネージ)か知るのは重要です
- TableauのGraphQLのAPIからWorkbookとBigQuery上のモデルの埋め込みの関係を知ることができます
- dbtのモデルとTableau上で使われているWorkbookの依存関係をexposureとして出力するスクリプトにより、dbtのジョブの失敗やテーブルの廃止がTableauのダッシュボードに与える影響などを調べやすくなりました
- 3行まとめ
- 背景
- 課題: dbtのexposureとしてダッシュボードを手動で記入し続けるのは難しい
- 解決方法: TableauのGraphQLのAPIを使い、 dbtのexposureを自動生成する
- 発展的話題
背景
業務において、DWHやデータマートの生成にdbtを、BIツールとしてTableauを利用しています。アナリストやアナリティクスエンジニアを中心にdbt経由でBigQuery上に多くのテーブルが日々作られ、それをデータソースとしてTableau上にダッシュボードが作成されています。データ活用の側面ではこれはよいことですが、データ管理の観点では考慮しないといけないことが増える側面もあります。例えば以下のようなことです。
- dbtのジョブが失敗した場合、どのテーブルに影響があるかはdbtのデータリネージから影響範囲が分かるが、Tableauのどのダッシュボードに影響があるか分からない
- 全てのダッシュボードのデータソースを把握するのは難しい
- 特にジョブが失敗したテーブルが複数がある場合、Tableauの検索画面から対象のダッシュボードを絞り込むのは困難です
- 求められるデータ品質に応じた対応をしたいが、その判断自体をするのが難しい
- 例: 閲覧者が多かったり、重要な目的のダッシュボードで使われているテーブルであれば急いで当日中に復旧
- 例: そうでなければ翌営業日までにゆっくり復旧
- 全てのダッシュボードのデータソースを把握するのは難しい
- テーブルを変更 / 廃止する際に影響が出るTableau上のダッシュボードを把握することが難しい
- 特に対象となるテーブルが多い場合
- BigQueryのINFORMATION_SCHEMAからはTableauのどのダッシュボードから発行されたクエリかは分からない
- Tableauがラベルに判別できる情報を含めてくれればよいのだが、現状は含まれていない
課題: dbtのexposureとしてダッシュボードを手動で記入し続けるのは難しい
これまで説明した課題に対し、dbtではダッシュボードをexposureとして表現するとテーブル(モデル)の依存関係にダッシュボードを加えることができます。exposureのdepends_onにモデル群を記述すればOKです。
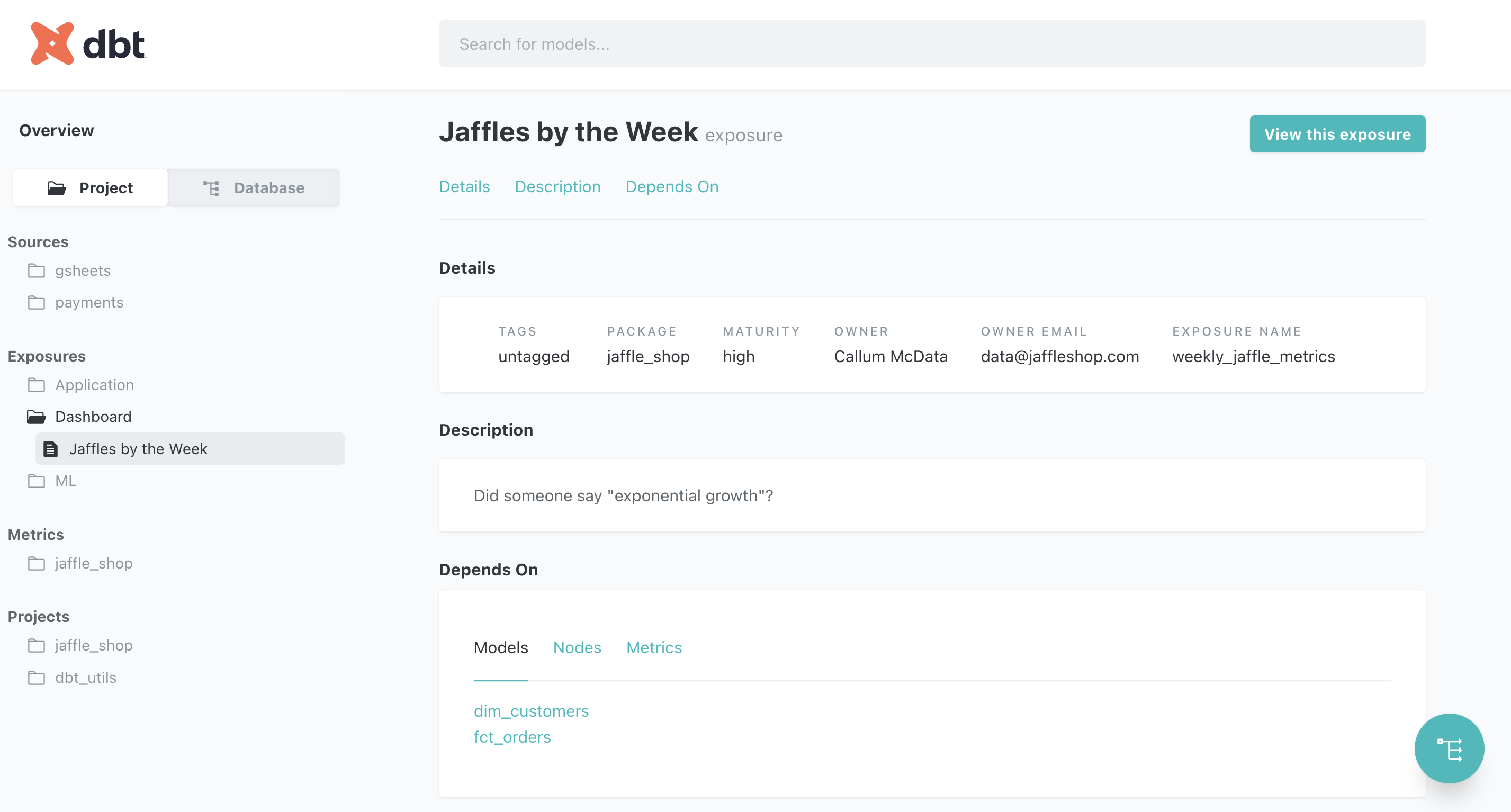
これにより、先ほど説明した課題は一見解決したかのように思えますが「exposureの運用管理をちゃんとやるのが非常に難しい」という別の課題が登場します。実際、ダッシュボードを作る度にexposureを記述するというのを業務でやってみたことがあるのですが、高い確率で忘れられますし、作られたダッシュボードに対してexposureのカバレッジの担保が全然足りない状況でした。また、ダッシュボードに関する情報(例: ダッシュボードのタイトルや説明、タグ / オーナー)のマスターはTableau上に記載されていくことが多いため、あっという間にexposureの情報は古くなっていきます。
こういった作業はどう考えても善意ベースではなく、自動化が必要です。
解決方法: TableauのGraphQLのAPIを使い、 dbtのexposureを自動生成する
自動化するためにTableauのAPIを色々調べました。その結果、TableauにはGraphQLのAPIが存在しており、今回の課題に対して必要なダッシュボード(Workbook)中に含まれるデータソースの一覧を取得できることが分かりました。
公式のSDKやRest APIも存在していますが、自分が調査した限りこれらは対応するデータソースがBigQuery上のどのテーブルであるかを情報として含んでいませんでした(Tableau上のデータソース名は変更可能であるため、BigQuery上のテーブル名との対応関係を調べるには片手落ちです。この情報をきちんと含んでいるのはGraphQLのAPIのみのようでした)。
なお、同様の目的の既存のOSSが存在することは確認していますが、以下の理由から自前でスクリプトを書きました。
- 現状の対応がSnowflakeのみ(BigQueryに未対応)であること
- TableauのAPIを使う際にusername / passwordの認証方法しかなく、Personal Access Tokenに対応していないこと
- チームで運用する際に辛い...
気が向いたら既存のOSSにコントリビュートするかもしれませんが、後述するようにexposureのmetaに色々情報を詰め込みたくなりそうで、それを考えると自前スクリプトのほうが気軽かもしれません。
今回書いたソースコード(クリックで開きます)
import json import re import os from typing import Dict, Any, Set, List import yaml import argparse import tableauserverclient as tsc QUERY = f""" {{ workbooksConnection(first: 1000) {{ nodes {{ id luid name projectName description tags {{ id name }} site {{ id uri name }} projectVizportalUrlId uri vizportalUrlId createdAt updatedAt owner {{ id name username }} sheets {{ id name }} embeddedDatasources {{ id name upstreamTables {{ database {{ name }} schema fullName connectionType }} hasExtracts }} }} }} }} """ def read_model_names_from_manifest(manifest_file_path: str) -> Set[str]: with open(manifest_file_path, "r") as f: return set([item["name"] for item in json.load(f)["nodes"].values()]) def get_workbook_dependencies( server: tsc.server, auth: tsc.PersonalAccessTokenAuth ) -> List[Dict[str, Any]]: with server.auth.sign_in(auth): return server.metadata.query(QUERY)["data"]["workbooksConnection"]["nodes"] def get_exposures( data: List[Dict[str, Any]], model_names: Set[str], tableau_server_address: str, ) -> List[Dict[str, Any]]: result = {"version": 2, "exposures": []} pattern = r"\[.*?\]\.\[(.*?)\]" for item in data: depends_on = [] for ds in item["embeddedDatasources"]: for t in ds["upstreamTables"]: if t["connectionType"] != "bigquery": continue match = re.search(pattern, t["fullName"]) if match and match.group(1) in model_names: depends_on.append(f"ref('{match.group(1)}')") if not depends_on: continue tmp = { # workbookの名前はユニークである必要があるため、luidを使用する。dbtの制約からアンダーバーに変換する "name": item["luid"].replace("-", "_"), "label": item["name"], "type": "dashboard", "url": f"{tableau_server_address}/#/site/{item['site']['name']}/workbooks/{item['vizportalUrlId']}/views", "owner": { "name": item["owner"]["name"], "email": item["owner"]["username"], }, "depends_on": depends_on, "tags": [tag["name"] for tag in item["tags"]], "meta": { "created_at": item["createdAt"], "updated_at": item["updatedAt"], "sheets": [{"id": sheet["id"], "name": sheet["name"]} for sheet in item["sheets"]], }, } result["exposures"].append(tmp) return result def main(): parser = argparse.ArgumentParser() parser.add_argument( "--tableau_server_address", type=str, required=True, ) parser.add_argument( "--tableau_token_name", type=str, required=True, ) parser.add_argument( "--site_id", type=str, required=True, ) parser.add_argument( "--manifest_file_path", type=str, required=True, ) args, _ = parser.parse_known_args() server = tsc.Server(args.tableau_server_address, use_server_version=True) tableau_auth = tsc.PersonalAccessTokenAuth( args.tableau_token_name, os.environ["PERSONAL_ACCESS_TOKEN"], args.site_id, ) data = get_workbook_dependencies(server, tableau_auth) model_names = read_model_names_from_manifest(args.manifest_file_path) result = get_exposures(data, model_names, args.tableau_server_address) print(yaml.dump(result, allow_unicode=True, sort_keys=False)) if __name__ == "__main__": main()
なお、今回は自分に必要だった埋め込みデータソースのみの対応になっていますが、カスタムクエリに対しても同様のことができるので、必要な人は自前で対応してみてください。
スクリプトは以下のように実行します。
% env PERSONAL_ACCESS_TOKEN=... \ python scripts/generate_exposures_by_tableau.py \ --tableau_server_address https://prod-apnortheast-a.online.tableau.com \ --tableau_token_name MY_TABLEAU_TOKEN \ --site_id MY_SITE \ --manifest_file_path path/to/target/manifest.json > models/exposures/tableau.yml
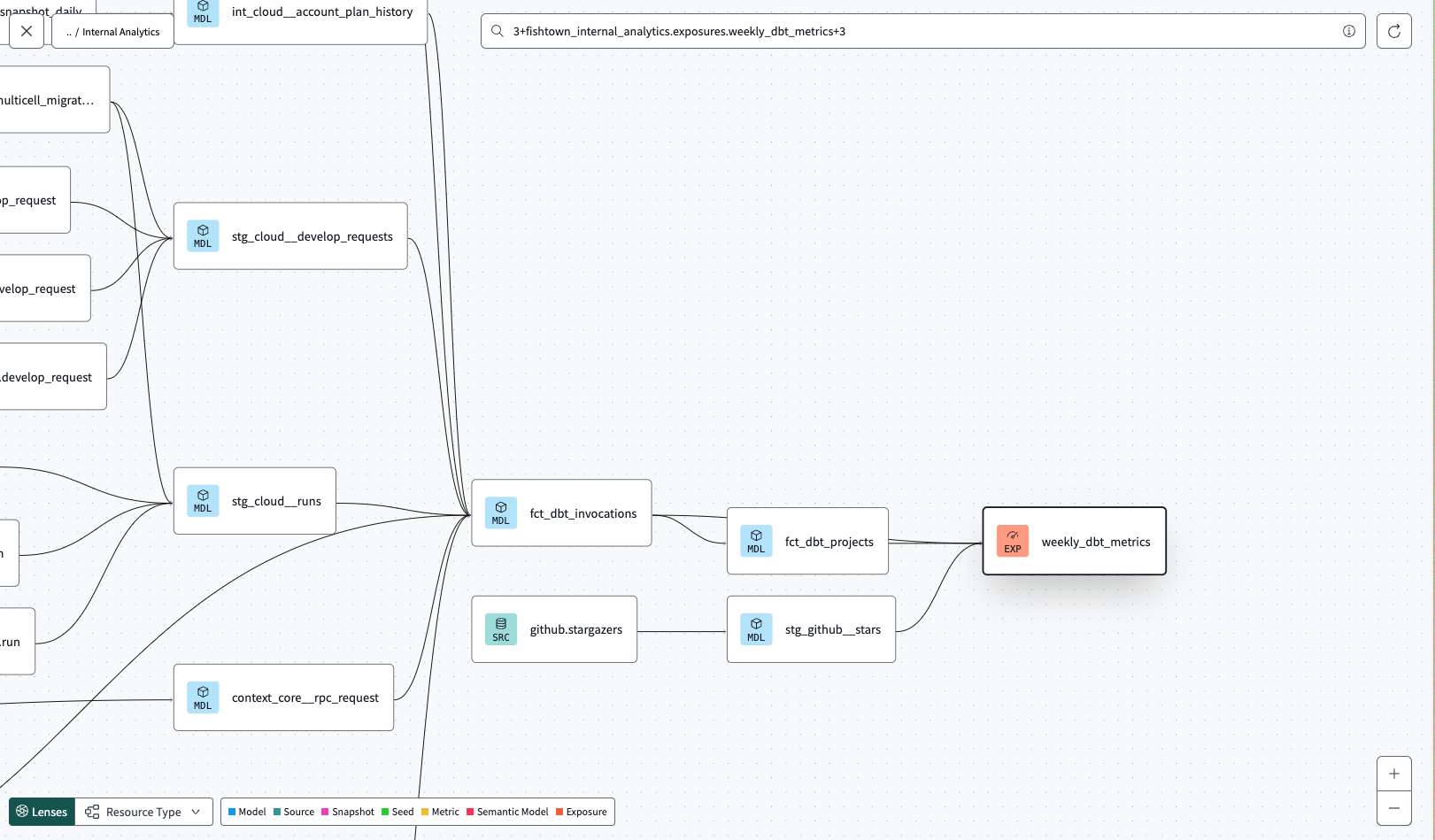
スクリプトを実行すると、以下のようなyamlが生成されます。このyamlを含んだ上でdbt docs generateを実行すると、dbtのリネージにTableau上のWorkbookも含まれるようになる、というわけです。
version: 2 exposures: - name: 123_abc_456_def label: ダッシュボード1 type: dashboard url: https://prod-apnortheast-a.online.tableau.com/#/site/MY_SITE/workbooks/12345/views owner: name: Yasuhisa Yoshida email: me@gmail.com depends_on: - ref('my_model1') - ref('my_model2') tags: - tag1 - tag2 meta: created_at: '2023-08-10T03:53:53Z' updated_at: '2023-08-21T06:10:05Z' sheets: - id: 123_abc_456_def name: シート1 - id: 123_abc_456_def name: シート1 - name: ...
発展的話題
TableauのWorkbookをdbtのexposureとして取り込めると、発展的に面白いことが色々できそうです。
- ダッシュボードやdbtのモデルの棚卸しの効率化
- TableauのAdvanced Managementを契約すると、Tableauの監査ログが取得できるようになる
- 「このワークブックに3ヶ月以内に閲覧した人の人数」などをスクリプト経由でmetaの情報に含んでおくことで機械的に棚卸ししやすくなり、データ管理を効率化できる
- Tableau上で必要とされている品質とdbt上の品質の食い違いを減らす
- 「このダッシュボード、色んな人が色んな業務で使っているからちゃんと管理してよ!」と言われてもすっごいアドホックでつぎはぎだらけのデータソースでは品質を担保することはできません
- 例えば、Tableau上で高品質であることが必要なワークブックには
maturity: highのラベルを付与するようにし、そういったワークブックのデータソースはアドホックなデータソースではなくデータエンジニアのチームが公式にサポートしているData Vaultを基盤にしたデータソースである(そうでなければアラートを鳴らすようにバッチを組んでおく)といった工夫ができると思います
- 今朝のバッチで影響の出ているTableauのWorkbookを機械的に洗い出す
- dbtの実行時には
invocation_idが紐付けられており、そのinvocation_idをキーにして失敗もしくはスキップされたモデルの一覧を取得することができます - TableauのWorkbookがdbtのexposureと紐付いており、elementaryでデータ品質をモニタリングしている場合、バッチの失敗で影響を受けているTableauのWorkbookの一覧をSQLでずばっと出力することができます
- Workbookのオーナーの情報なども入っているので、障害発生後の連絡もやりやすいですね
- dbtの実行時には
簡単な割に色々遊びがいがあると思うので「こういう場面でも役に立ったよ!」という事例があったら是非教えてください。Enjoy!
