アクセスログ解析をやってみよう
内容
- Rでの実際のデータ解析の流れを傍観してみる
- 必要な定型(?)作業とかを確認
- Tsukuba.R#1のデータ構造とかがどう生きてくるかを見る
- 適宜説明していくので、どうにかなるようにします
Tsukuba.R#1
- Rに付属のデータで色々やってみた
- data()
- 便利だけど、あんまり面白くはない
- じゃあ、身近なデータで遊んでみよう
- あんまり高度な統計解析を使わない範囲で
そういうわけでアクセスログ解析
- みんな割りと見ているかもしれない
今回使うデータ
- id:syou6162のBlogのアクセスログ(をスクレイピングしてきたやつ)
- 去年の1月から11月までの毎日のアクセス数のデータ
- 曜日とかの情報も付加されている
このデータを使って
- 月ごと、曜日ごとの特徴を簡単に知るところくらいまでをやろう
- Tsukuba.R#1の実践と復習くらいの軽い内容
まず、生のデータを見てみよう
- ToDo:tab区切りのデータが置いてあるurlを書く
- http://infoshako.sk.tsukuba.ac.jp/~yoshid50/count.txt
read.table("http://infoshako.sk.tsukuba.ac.jp/~yoshid50/count.txt")
データの形式
- 空白区切りのデータ
- データを読む時には区切り文字重要!
- 使う関数「read.table」
- 半角区切りやタブ区切りのデータに対して使用
- cf.「,」区切りのcsvデータ
- データの形式としてはよくある形
- read.csv
テキストファイルが置いてあるパスを指定
- 絶対パスでもよいし、相対パスでもよい
- 相対パスの時には自分がどこにいるかを確認したい
- 「getwd」関数
- 作業ディレクトリの変更
- guiでもできる
setwd("~/Desktop")
カレントディレクトリにファイルがあるなら
- headerはカラム名として使用するかどうかのオプション
- 使い方を忘れたら、「?read.table」
read.table("count.txt",header=TRUE)
データフレーム
- 「<-」は代入の演算子
count <- read.table("count.txt",header=TRUE)
欲しい結果になっているか確かめよう
- str関数
- データの構造(structure)を見るための関数
- どうやら欲しいデータフレームの形になっているらしい
> str(count) 'data.frame': 334 obs. of 4 variables: $ day : int 1 2 3 4 5 6 7 8 9 10 ... $ month: int 1 1 1 1 1 1 1 1 1 1 ... $ week : int 1 2 3 4 5 6 0 1 2 3 ... $ count: int 15 38 55 35 74 68 39 32 55 66 ...
追加的な説明:欠損値の確認
- 実験データとかアンケートデータとか欠損値がつきもの
- データ形式が正しくても欠損値があるとあとの統計解析がきちんとできない
- →欠損値の確認をすることが大切
- でも、データがでかいと目ではやってられない
わざとらしいデータで実験してみる
- 行列で、is.na関数を試してみる
- na = not available
m <- matrix(c(1,2,NA,4,5,6,7,NA,9,10,11,12),3,4) is.na(m) m apply(m,1,function(x){all(!is.na(x))}) all(apply(m,1,function(x){all(!is.na(x))}))
apply関数になれてないよ><っていう人は
- complete.casesを使えばどうにかなる
complete.cases(m) m[complete.cases(m),] all(complete.cases(count))
ただ
- やたらと関数名を覚えまくるよりは
- 使い勝手のよい基本的な関数とapplyファミリーの関数を組み合わせていったほうが
- R的でいいんじゃないかな…!!
データ解析的な視点で行くと
- 「欠損値だからcomplete.casesで消しちゃえ」的なことは気軽にはやらないように
- なるべく埋める努力を
- どーーーしても無理っていうもののみを欠損値として扱うようにしませう
データ全体の特徴を見よう
- さっきのは構造
- 今度は特徴
- 何か要約を見たいと思ったら「summay関数」!!
> summary(count) day month week count Min. : 1.00 Min. : 1.000 Min. :0 Min. : 15.00 1st Qu.: 8.00 1st Qu.: 3.000 1st Qu.:1 1st Qu.: 53.00 Median :16.00 Median : 6.000 Median :3 Median : 72.00 Mean :15.69 Mean : 6.018 Mean :3 Mean : 82.55 3rd Qu.:23.00 3rd Qu.: 9.000 3rd Qu.:5 3rd Qu.: 99.00 Max. :31.00 Max. :11.000 Max. :6 Max. :952.00
summary関数のおさらい
- summay関数は総称的関数の一つ
- 投げたデータの型に対して、適当に要約をしてくれる
- 今回はSpeciesに注目
- 投げたデータの型に対して、適当に要約をしてくれる
> str(iris) 'data.frame': 150 obs. of 5 variables: $ Sepal.Length: num 5.1 4.9 4.7 4.6 5 5.4 4.6 5 4.4 4.9 ... $ Sepal.Width : num 3.5 3 3.2 3.1 3.6 3.9 3.4 3.4 2.9 3.1 ... $ Petal.Length: num 1.4 1.4 1.3 1.5 1.4 1.7 1.4 1.5 1.4 1.5 ... $ Petal.Width : num 0.2 0.2 0.2 0.2 0.2 0.4 0.3 0.2 0.2 0.1 ... $ Species : Factor w/ 3 levels "setosa","versicolor",..: 1 1 1 1 1 1 1 1 1 1 ... > summary(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Min. :4.300 Min. :2.000 Min. :1.000 Min. :0.100 1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300 Median :5.800 Median :3.000 Median :4.350 Median :1.300 Mean :5.843 Mean :3.057 Mean :3.758 Mean :1.199 3rd Qu.:6.400 3rd Qu.:3.300 3rd Qu.:5.100 3rd Qu.:1.800 Max. :7.900 Max. :4.400 Max. :6.900 Max. :2.500 Species setosa :50 versicolor:50 virginica :50
データフレームのある列を取得する
- 「count[,4]」とかでアクセスが可能
- 「行は全部、列は4列目」というようなイメージ
でも、こういうことはあんまりしない(かもしれない)
- カラム名を付けているんだったら、カラム名でアクセスしたい
- 「データフレーム$カラム名」でアクセスできる
- 「count$count」
- ちょっと分かりづらいけど。。。
> head(count$count,n=30) [1] 15 38 55 35 74 68 39 32 55 66 41 56 39 51 64 60 83 39 65 46 74 92 52 50 65 [26] 29 40 35 69 56
アクセス数の傾向を把握する
- 「増加しているのか、減少しているのか」、「周期性があるのか、ないのか」etc
- そんな時はplot関数
- とりあえずベクトルデータを投げてみよう
plot(count$count)
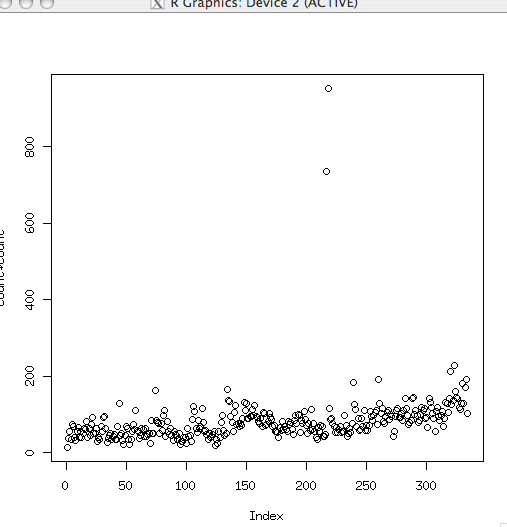
**異常値が邪魔して傾向が読み取れない>
- 実際のデータ解析にはよくあること
- とりあえず異常値にあんまり関係なさそうな250未満のところを見ればいいんじゃないか
- 値域の値(y軸のほう)を制限
- ylimにベクトルデータを与えてあげる
- Rでのベクトルデータの生成はc関数
plot(count$count,ylim=c(0,250))
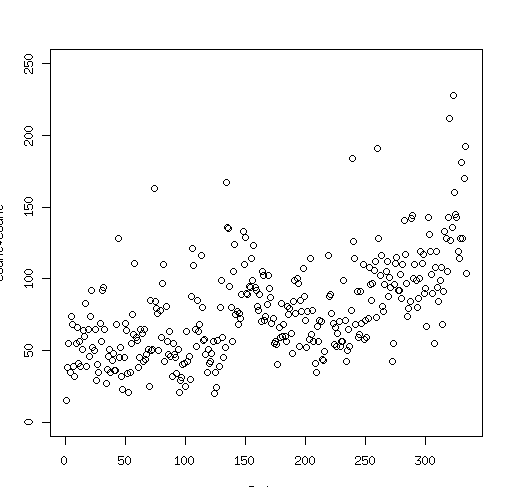
脱線
- plotが味気無い
- 色々装飾したい
- ラベルを付けたい
- etc
- X11だから微妙に汚ない。。。
plot(count$count,ylim=c(0,250),col="red",type="l",xlab="経過日数",ylab="ユニークアクセス数",main="アクセス数の推移")
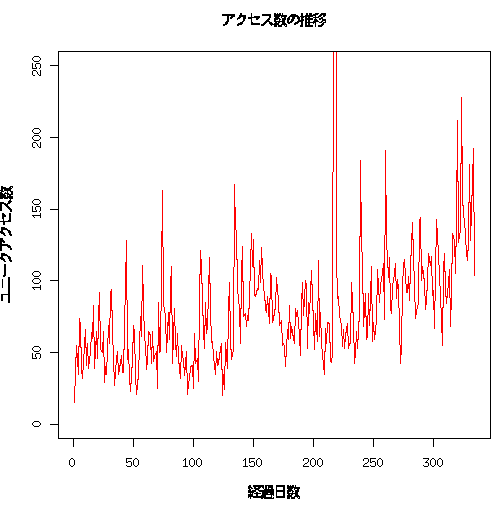
平滑化曲線
- 詳しい説明は省きます
- ノンパラとか詳しい人説明してくだしあ
- でも、経過と共にアクセス増えてるかなーっていう傾向はなんとなく掴めてきた
lines(lowess(seq_along(count$count),count$count,f=.2),col="blue")
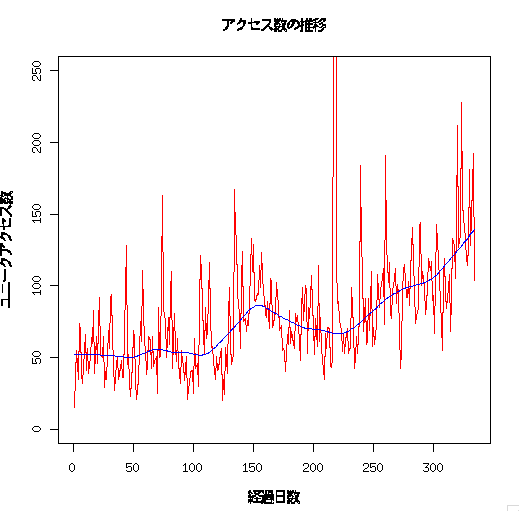
そもそも、月毎の平均をplotすればいいんじゃない?
- ごもっとも
- 難しい解析ができるからってよいわけじゃない
- 「月毎の平均」自分だったら、どう集計しますか?
- Rらしい解析の方法って?
各月で条件付けていく方法
- めんどくさい
- 平均じゃなくて、median(中央値)を出したくなったらもう一回やらないといけない
#条件に合うところを抽出 count$month == 1 count$count[count$month == 1] month_mean <- c() #ベクトルに代入を各月で繰り返す month_mean[1] <- mean(count$count[count$month == 1])
そこでapplyファミリーですね、分かります
- applyファミリーはデータフレームやベクトル、リストを引数に取って、関数を適用する関数
- 色々種類があった
- 何かの種類ごとの統計量を求めたい
- そんな時はtapply関数!!
実際にやってみる
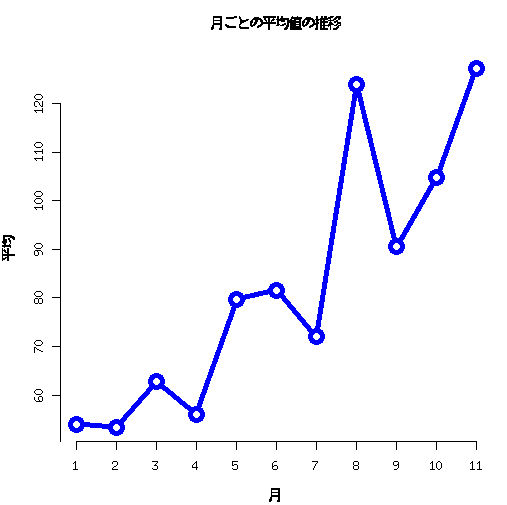
> tapply(count$count,count$month,mean) 1 2 3 4 5 6 7 8 54.03226 53.39286 62.74194 56.06667 79.77419 81.60000 72.00000 124.00000 9 10 11 90.50000 104.77419 127.16667
月ごとの平均値をplotしてみる
- 8月は異常値があったせいで平均値が引っぱられている
plot(tapply(count$count,count$month,mean),pch=21,type="b",xlab="月",ylab="平均",main="月ごとの平均値の推移",axes=F,lwd=5,cex=2,lty=1,col=4) axis(1,1:11,1:11,) axis(2,seq(40,120,by=10))
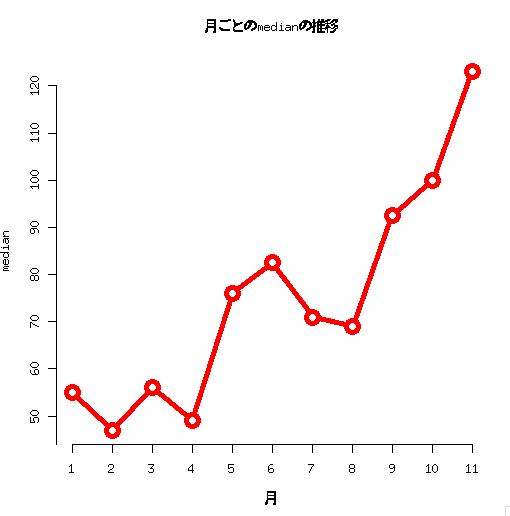
medianに変更するのもtapplyなら簡単
plot(tapply(count$count,count$month,median),pch=21,type="b",xlab="月",ylab="median",main="月ごとのmedianの推移",axes=F,lwd=5,cex=2,lty=1,col=2) axis(1,1:11,1:11,) axis(2,seq(40,120,by=10))
れんしゅーもんだい
- 同じ要領で、曜日ごとの平均をplotしてみよう
- こんなイメージ
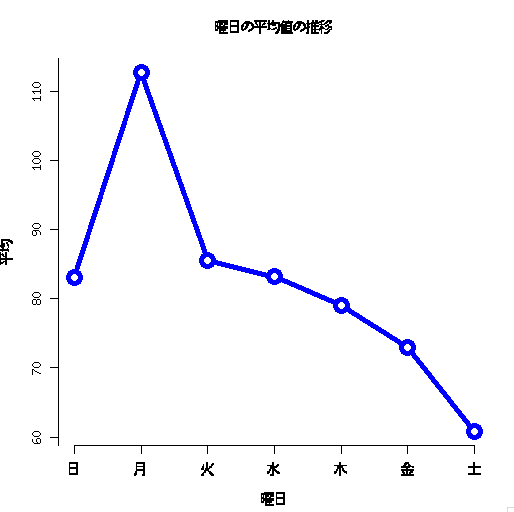
回答
plot(tapply(count$count,count$week,mean),pch=21,type="b",xlab="曜日",ylab="平均",main="曜日の平均値の推移",axes=F,lwd=5,cex=2,lty=1,col=4) axis(1,1:7,c("日","月","火","水","木","金","土"),) axis(2,seq(40,120,by=10))
データ解析は一日にして終わらずorz
- 加工したデータとかセッションの保存
- 研究とかで使うんだったら必須な感じかも
- R以外でのアプリケーションとのデータのやりとりとか
csvやタブ区切りのデータとして出力
- writeほげほげ関数
- 必要に応じた形で
write.table(count, file = "~/Desktop/count.txt") write.csv(count, file = "~/Desktop/count.csv")
Rのデータ構造をそのまま持っておきたい
- list形式のデータとか
- カラム名とかやたら工夫したdata.frameとか
dput(count,"~/Desktop/count") rm(count) dget("~/Desktop/count")
save、load関数
- 記録は内部形式で行なわれる
- エディタとか見ることはできない
その他のデータ形式での出力
- ライブラリとかで色々できるっぽい
- xml
- yaml
まとめ
- データの読み込み
- 構造、欠損値のチェック
- データの要約を見る
- 解析をする
- 時系列解析なり、回帰分析なり、クラス分類なり
- 異常値とかに対して、処理をする
- データの出力
- pngなり、csvなり
- これを無限ループ(ry
以上
- 泥なデータ解析を少しでも楽をしましょう!!