背景 & やりたいこと
私が所属している10Xでは、これまでもパートナー向けにダッシュボードを提供したり、社内のデータウェアハウスをdbtで構築したりと、データ品質は重視してきました。2025年の夏から新しいデータプロダクトの運用が始まり、さらに高い品質が求められるようになりました。私たちが開発・運用するデータパイプラインの品質が、そのままデータプロダクトの品質に直結するためです。
このデータプロダクトは実際の発注業務に直接影響を与えるため、これまで以上に慎重な品質管理とリリース前確認が必要です。何か問題が起きてから対処するよりも、大きな問題が起きる前に事前に気づける環境を構築したいと考え、QA環境の導入を決めました。
これまでのdbtリリースフローと課題
これまでのリリースフローは、一般的なdbtプロジェクトで採用されている手順に沿ったものでした。Pull Requestを上げるとCI/CD環境でdbtのジョブが実行されます。本番環境とは別に開発環境もあるため、そこでも確認できます。dbtのmaterialized=tableやviewのようなステートレスなモデル(データの洗い替え)については、CI/CD環境や開発環境で動けば問題ありません。
しかし、incrementalモデルで日々データを積んでいく場合は、以下の課題がありました。
- 環境間のデータ差異
- 開発環境と本番環境のデータの蓄積がずれている
- CI/CDでは、バッチ処理がコスト最適化のため当日分あるいは直近数日分のデータしか処理しないことが多い
- CI/CDで処理した日付以外のデータで本番環境で初めて不具合が発覚
- スキーマ変更時の問題
incrementalモデルやdbt snapshotの場合、カラムの追加・削除・型変更といったスキーマ変更を行うと過去分がNULLになる- Data Vault(データの履歴管理に特化したモデリング手法)を使う場合、スキーマ変更によりHashDiff(レコードの全カラムから計算されるハッシュ値で、Satelliteテーブルでレコードの変更を検知するために使用)が変わる
- 本質的な変更がないのにレコードが変わったように見える
incrementalモデルの状態に依存しない確認環境が必要
- データ参照期間の制限
- 開発環境やCI/CDではデータ参照期間が短い
- 本番にリリースしないと長期間のデータでの問題が分からない
QA環境の設計と実装
dbt cloneの選定理由
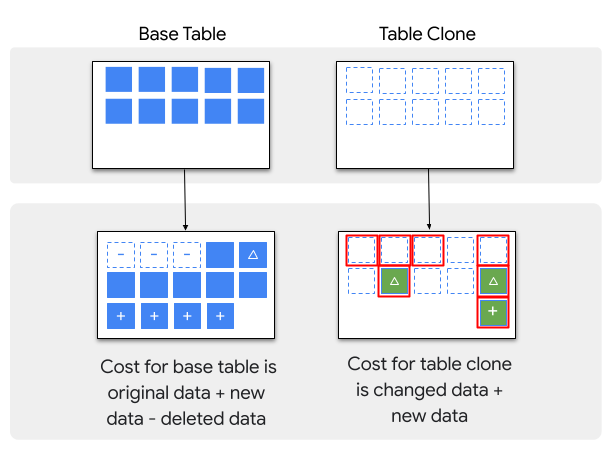
QA環境はリリース前の最終確認時のみ使用するため、本番環境のテーブルをフルコピーしても大きなコストはかかりません。とはいえ少しでもコストを抑えたいため、dbt cloneを選択しました。LayerXさんがBigQueryやSnowflakeで同様の環境を構築した記事を参考にしました。
正確にはdbt cloneそのものというよりも、その基盤となるゼロコピークローン機能が優れているという点が重要です。BigQuery、Snowflake、Databricksなどのモダンなデータウェアハウス製品がこの機能をサポートしており、今回はBigQueryのテーブルクローン機能を活用しました。以下の特徴があります。
- 元のテーブルに影響を与えない
- クローン後のテーブルに
incrementalモデルでレコードを積んでも問題ない - コストは差分のみで済むため気軽に使える
テーブルクローンの仕組みとコスト構造は以下の図の通りです。元テーブルのデータは複製されず、クローンテーブルで変更されたデータ(差分)のみがストレージに保存され課金されます。
(出典: BigQueryドキュメント - テーブルクローンの概要)
インフラ構成と実装
QA環境は本番環境に影響を与えないよう、別のGoogle Cloudプロジェクトで構成しています。データセットは本番環境と同じスキーマ構成とし、Cloud Run Jobsを使用しました。チーム全員がCloud Run Jobsに習熟しているため、運用面でのハードルが低く抑えられます。
本番環境で毎日生成しているdbtのartifact(特にmanifest.json)を取得して、dbt cloneの--stateや--deferオプションを使ってクローンを実行します。具体的には以下のような流れです。
# 本番環境で生成されたmanifest.jsonをGCSから取得 mkdir -p ./artifacts/prod_run gsutil cp gs://my-project-artifacts/prod/manifest.json ./artifacts/prod_run/manifest.json # dbt cloneでincrementalモデルをクローン dbt clone --target qa --select "tag:qa_clone" \ --full-refresh --state ./artifacts/prod_run # その他のモデルを実行 dbt run --target qa --defer --defer-state ./artifacts/prod_run dbt test --target qa --defer --defer-state ./artifacts/prod_run
GitHub Actionsでは、手動トリガー(workflow_dispatch)でDocker imageをビルドしてArtifact Registryにpushし、Cloud Run JobsのコンテナイメージURLを更新するワークフローを構築しました。ブランチ名からタグを自動生成する仕組みも組み込んでいます。
on: workflow_dispatch: jobs: push_container_images: runs-on: ubuntu-latest outputs: tag: ${{ steps.generate_tag.outputs.tag }} steps: - name: Checkout repository uses: actions/checkout@v4 - name: Generate tag from branch name id: generate_tag run: | BRANCH_NAME="${{ github.ref_name }}" TAG_NAME="${BRANCH_NAME//\//_}" echo "tag=$TAG_NAME" >> "$GITHUB_OUTPUT" - name: Authenticate to Google Cloud id: auth uses: google-github-actions/auth@v2 with: token_format: access_token workload_identity_provider: "projects/123456789/locations/global/workloadIdentityPools/github-actions/providers/github-actions-provider" service_account: "gha-workflows@my-project.iam.gserviceaccount.com" - name: Set up Docker Buildx uses: docker/setup-buildx-action@v3 - name: Login to Artifact Registry uses: docker/login-action@v3 with: registry: asia-northeast1-docker.pkg.dev username: oauth2accesstoken password: ${{ steps.auth.outputs.access_token }} - name: Build and push uses: docker/build-push-action@v6 with: context: ./dbt push: true tags: asia-northeast1-docker.pkg.dev/my-registry-project/dbt-repository/main:${{ steps.generate_tag.outputs.tag }} update_cloud_run_jobs: runs-on: ubuntu-latest needs: push_container_images steps: - name: Authenticate to Google Cloud uses: google-github-actions/auth@v2 with: workload_identity_provider: "projects/123456789/locations/global/workloadIdentityPools/github-actions/providers/github-actions-provider" service_account: "gha-workflows@my-project.iam.gserviceaccount.com" - name: Update Cloud Run Job image run: | gcloud run jobs update "dbt-batch-daily-qa" \ --image="asia-northeast1-docker.pkg.dev/my-registry-project/dbt-repository/main:${{ needs.push_container_images.outputs.tag }}" \ --region="us-central1" \ --project="my-project-qa"
QA環境のCloud Run Job自体はTerraformで管理していますが、使用するコンテナイメージのバージョン(タグやdigest)はlifecycleのignore_changesに設定することで、インフラのライフサイクルとイメージ更新のライフサイクルを分離しています。これにより、GitHub Actionsからのイメージ更新とは別に、Cloud Run Jobsのコンソールから手動で実行することもできます。
resource "google_cloud_run_v2_job" "dbt_batch_daily_qa" { name = "dbt-batch-daily-qa" location = "us-central1" template { template { containers { image = "asia-northeast1-docker.pkg.dev/my-registry-project/dbt-repository/main" # ... } } } lifecycle { ignore_changes = [ template[0].template[0].containers[0].image ] } }
これにより、Terraformはインフラの構成管理に集中し、イメージバージョンの更新はGitHub Actionsから自由に行えるようになります。
運用ドキュメントには、BigQueryのテーブル詳細画面で「Clone of」表示があることでクローンテーブルと判別できること、QAテーブルの配置場所(データセット名やプロジェクト名)を記載しました。
実装上の工夫ポイント
基本的なQA環境の構築は上記の通りですが、Data Vaultを使用している場合には追加の工夫が必要でした。スキーマ変更やカラム追加時に特有の課題があります。HashDiffはレコードの全カラムから計算されるハッシュ値で、Satelliteテーブルでレコードの変更を検知するために使用されます。しかし、スキーマ変更により値が変わってしまいます。その結果、本質的な変更がないのに新しいレコードとして再挿入される問題が発生します。
例えば、Satelliteテーブルsat_customerが以下の状態だったとします。
| customer_key | load_timestamp | name | age | hashdiff |
|---|---|---|---|---|
| h1 | 2024-01-01 00:00:00 | 田中太郎 | 30 | aaa111 |
| h1 | 2024-02-01 00:00:00 | 田中太郎 | 31 | bbb222 |
| h2 | 2024-01-15 00:00:00 | 佐藤花子 | 25 | ccc333 |
ここでemailカラムを追加し、2024-03-01に新しいソースデータ(佐藤花子: name=佐藤花子, age=25, email=hanako@example.com)が到着した場合、通常のdbt clone→dbt runでは以下のようになります。
| customer_key | load_timestamp | name | age | hashdiff | |
|---|---|---|---|---|---|
| h1 | 2024-01-01 00:00:00 | 田中太郎 | 30 | NULL | aaa111 |
| h1 | 2024-02-01 00:00:00 | 田中太郎 | 31 | NULL | bbb222 |
| h2 | 2024-01-15 00:00:00 | 佐藤花子 | 25 | NULL | ccc333 |
| h2 | 2024-03-01 00:00:00 | 佐藤花子 | 25 | hanako@example.com | eee555 |
| h1 | 2024-03-01 00:00:00 | 田中太郎 | 31 | NULL | ddd444 |
h1(田中太郎)の2024-02-01のレコード(bbb222)と2024-03-01のレコード(ddd444)は、nameとageは同じですが、HashDiffの計算式が変わったため(hash(name|age) → hash(name|age|email))、異なるHashDiffとして認識されます。AutomateDVのLAG()比較でbbb222 != ddd444となり、変更なしなのに新レコードとして挿入されてしまいます。
この問題を回避するにはincrementalモデルのテーブルを削除してdbt runやdbt testを実行する必要がありますが、クローンを実行すると削除したテーブルが復元されてしまいます。
そこでWITHOUT_DBT_CLONE環境変数を導入し、クローンをスキップしながらデータ追加操作を行えるようにしました。スクリプトでは以下のように条件分岐を実装しています。
artifact_dir="./artifacts/prod_run" # WITHOUT_DBT_CLONE環境変数が未設定の場合のみcloneを実行 if [ -z "${WITHOUT_DBT_CLONE:-}" ]; then dbt clone --target qa --select "tag:qa_clone" \ --full-refresh --state "${artifact_dir}" fi # その他の処理は常に実行 dbt run --target qa --defer --defer-state "${artifact_dir}" dbt test --target qa --defer --defer-state "${artifact_dir}"
また、どのモデルにクローンが必要かを判断するためのtag:qa_cloneを設けました。viewやtableは洗い替えされるためクローン不要ですが、incrementalモデルのテーブルはクローン対象とし、Data Vaultを使う場合はraw_vaultレイヤー(生データを格納する基底レイヤー)に付与します。具体的には、dbt_project.ymlでは以下のように設定します。
models: my_project: raw_vault: +tags: ["qa_clone"] +materialized: incremental
実装中に遭遇した課題
QA環境の構築自体は上記の通りスムーズに進みましたが、Google Cloudのプロジェクト間で権限設定する際に手間がかかりました。
- QA環境と本番環境は別プロジェクト
- 参照するデータソース、
incrementalモデルのテーブル、GCS(dbtのartifact保存用)は本番環境にある - クロスプロジェクトかつデータセット単位で権限を設定する必要がある
- BigQueryでは
roles/bigquery.dataViewer(データセット単位) - GCSでは
roles/storage.objectViewer(バケット単位) - QA環境のService Accountに対して本番環境のリソースへのアクセス権を付与
- BigQueryでは
具体的には、QA環境のService Account(例: qa-dbt@my-project-qa.iam.gserviceaccount.com)に対して、本番環境の各データセットとGCSバケットへの読み取り権限を個別に付与する必要がありました。一度設定すれば問題ありませんが、初回はデータセットやバケットの数だけ設定が必要で、やや面倒でした。
QA環境の効果と今後
QA環境を何回か使い、本番リリース前の確認を行っています。CI/CDではテストが成功したものの、QA環境で初めて問題が発見された例がいくつかありました。本番に出す前にきちんと確認できるため、開発者として安心して開発を進められます。
動作確認では、以下のようなSQLクエリを使ってQA環境と本番環境のテーブルの差分をレコードレベルで確認しています。
with prod as ( select * from `my-project.dataset_name.table_name` ), qa as ( select * from `my-project-qa.dataset_name.table_name` ) select * from (select * from prod except distinct select * from qa) union all select * from (select * from qa except distinct select * from prod)
このクエリは、本番環境とQA環境のテーブル間の差分レコードを抽出します。QA環境でdbt runを実行した後、Pull Requestで追加・変更したロジックが意図通りに動作しているかを確認するために使用します。差分があった場合、それが意図した変更によるものか、予期しないバグによるものかを判断できます。
現時点で大きな問題はありませんが、以下の改善余地があります。
- QA環境と本番環境の差分確認を素早くできるようにする
- 差分確認方法を標準化し、人によらない方法を確立する
まとめ
全てのdbt運用環境にQA環境が必要とは考えていません。ただし、データプロダクトなど特に高い品質が求められる場合、事故を起こさないことが求められる場合においては、QA環境の導入はそれほど多くの手間が必要なわけではありません。そういったケースでこのエントリーが参考になれば幸いです。