会場なう。ということで、資料を置いておきます。
やっちろ.R in 熊本
今日のAgenda
- 自己紹介
- Tsukuba.Rについて
- 事前調査
- Rのぐぐり方、効率がよい(と思われる)勉強の仕方
- Rのデータ構造とそれに関する関数
- ベクトル、行列、データフレーム、リスト
- 因子型、層別分析
- apply family
はじめまして!!
- id:syou6162
- 吉田康久
- please call me syou!!
- 筑波大学院の修士一年生
- Tsukuba.Rを運営している中の人
普段使っている言語
- R
- Ruby
- C++
Tsukuba.Rについて
- できた理由
- RubyKaigi
- 当日スタッフで参加
Rubyのコミュニティ楽しそう!!
- Rにもこういうコミュニティがあったらいいなあ
- RubyKaigi打ち上げ
- Ruby札幌++
- じゃあ、自分で作るか
- Tsukuba.Rでけた!!
事前調査【頻度編】
- まだRのインストールしてな(ry
- Rのインストールはしてある
- 週一回くらいの頻度では使っている
- 週一回くらいの頻度では使っている
- ほぼ毎日使っている
事前調査【Rの知識編】
- ぶっちゃげ何も知らな(ry
- read.csvとかでファイルを読めることくらいは知っている
- plotとかすると何かできることを知っている
- Rにおける基本的なデータ構造を知っている
- 総称関数が分かる
- 自分でパッケージ書いたことがある
- Cによる拡張を書いたことがある
事前調査【統計知識編】
- データの読み書き、plotくらいはやったことがある
- 大学なりどこかで回帰分析くらいは勉強した記憶がある人
- 統計、データマイニング、機械学習を勉強したことがある、または研究している
ご協力ありがとうございます
Rの勉強会でよく聞かれること
- 「Rってぐぐりづらいよね」
- 「アルファベット一文字のプログラミング言語使ってる人って(ry」
Rのぐぐり方
- Rでの検索の方法
- Rの勉強の仕方
まとめ
- Rに聞く
- Rでのkeywordを覚える
- ハブサイトを押さえる
R
- RのことはRに聞け
- 分からないことはぐぐらずともRに聞く
keyになる関数
- ?hoge
- help("hoge")
- example(hoge)
「?hoge」
- hogeに関することを調べる
- データに関すること
- 関数に関すること
「example(hoge)」
- どんなんかは何となく分かった
- 実例が見たい
- そんな時に
その他
- example(example)とかすればいいと思います
- help.search("foo")
- demo(graphics)
関数定義を見る
- 関数名をそのままtype
- predict.lm
- 大体はこれでおk
余談
- 総称的関数
- cf.methods("predict")
- RにおけるOOPを実現
見れない関数もある
- predict.arとか
- 「 エラー: オブジェクト "predict.ar" は存在しません 」
- 存在しないんじゃなくて、公開されていない→隠蔽されている
隠蔽されている関数のことも見たい
- getAnywhere("predict.ar")
Rでのkeywordを覚える
- 基本的なデータ構造やデータ型
- 基本的な関数とか
- 質問がしやすくなる(人とかgoogleとか)
- この手のは本で勉強するとよいかも
- あとで説明
本の紹介
- あさましいリンクを張って(ry

The R Tips―データ解析環境Rの基本技・グラフィックス活用集
- 作者: 舟尾暢男
- 出版社/メーカー: 九天社
- 発売日: 2005/02
- メディア: 単行本
- 購入: 3人 クリック: 20回
- この商品を含むブログ (34件) を見る

- 作者: U.リゲス,石田基広
- 出版社/メーカー: シュプリンガー・ジャパン(株)
- 発売日: 2006/10/22
- メディア: 単行本
- 購入: 14人 クリック: 114回
- この商品を含むブログ (47件) を見る

データによるプログラミング―データ解析言語Sにおける新しいプログラミング
- 作者: JohnM. Chambers,垂水共之,水田正弘,山本義郎,越智義道,森裕一
- 出版社/メーカー: 森北出版
- 発売日: 2002/02
- メディア: 単行本
- クリック: 4回
- この商品を含むブログ (2件) を見る
")
Rプログラミングマニュアル (新・数理工学ライブラリ 情報工学)
- 作者: 間瀬茂
- 出版社/メーカー: 数理工学社
- 発売日: 2007/11
- メディア: 単行本
- 購入: 4人 クリック: 90回
- この商品を含むブログ (29件) を見る

- 作者: 金明哲
- 出版社/メーカー: 森北出版
- 発売日: 2007/10/01
- メディア: 単行本(ソフトカバー)
- 購入: 36人 クリック: 694回
- この商品を含むブログ (64件) を見る
ハブサイトを押さえる
- とりあえず最低限ここは
- 実際のcodeを見てみたいとか
Blog
順番等は特に関係ありません。
- Taglibro de H:So-netブログ
- タグ「r」を検索 - はてなブックマーク
- Rに関するkkobayashiのはてなブックマーク
- http://itoshi.tv/d/
- http://www.r-cookbook.com/
- Great oaks from little acorns grow.
- ryamadaの遺伝学・遺伝統計学メモ
- http://www.ai.cs.kobe-u.ac.jp/~kawamura/index.html
- 統計ソフトRのブログ
- ドレッシングのような
- Inleiding tot de R-statistiek
- Drkcore
- http://www.okada.jp.org/RWiki/?R%A5%B7%A5%E9%A5%D0%A5%B9
というわけで、ここから本題
- Agenda
- Rのデータ構造、それに関連する便利な関数とかを紹介
- "Rらしい"ところを説明する予定
データ構造
- ベクトル
- 行列
- リスト
- データフレーム
- 因子
- …
ベクトル
mydata <- c(1,2,3,4,5,6,7,8,9,10)
最小単位がベクトル
> 1 [1] 1 > is.vector(1) [1] TRUE
Rの格言
- 「意味のあるときは常に、意味の無いときも常にベクトル化を心がけよ」
- ベクトル志向の関数が色々ある
- 登場する度に紹介
規則的データの生成
- Rubyの1..10みたいな
> 1:10 [1] 1 2 3 4 5 6 7 8 9 10
ベクトルへのアクセスの方法
- []
- シーケンスを投げると、部分ベクトルにして返してくれる
- ベクトルのインデックスが0からではなく1から始まるところが慣れないところかも
> mydata [1] 1 2 3 4 5 6 7 8 9 10 > mydata[5] [1] 5 > mydata[3:5] [1] 3 4 5
アクセス方法にもいろいろある
- 論理値でTRUEのところだけを返す
> mydata[mydata > 3] [1] 4 5 6 7 8 9 10 > mydata > 3 [1] FALSE FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
まだまだあるよ、アクセス方法
- 負の引数を取ると、そこを除いてベクトルにして返す
- 末尾のほうを見る言語に慣れている人はややこしく感じるところかも
- []の中にc関数で負の値を入れておくと、複数個を取り除くこともできる
- perlとかとは違う
> mydata[-10] [1] 1 2 3 4 5 6 7 8 9 > mydata[-1] [1] 2 3 4 5 6 7 8 9 10 > mydata[c(-1,-2)] [1] 3 4 5 6 7 8 9 10
行列
- matrix関数
- ベクトルを行列に変換
- 列から順に決まっていく
> matrix(mydata,2,5) [,1] [,2] [,3] [,4] [,5] [1,] 1 3 5 7 9 [2,] 2 4 6 8 10
埋めていく順番
- byrow=Tをやると行から埋めていくことができる
> matrix(mydata,2,5,byrow=T) [,1] [,2] [,3] [,4] [,5] [1,] 1 2 3 4 5 [2,] 6 7 8 9 10
すでにあるベクトルを束ねる
- cbind
- rbind
> a <- c(1,2,3,4) > b <- c(5,6,7,8) > c <- c(9,10,11,12) > d <- cbind(a,b,c) > d a b c [1,] 1 5 9 [2,] 2 6 10 [3,] 3 7 11 [4,] 4 8 12
行列へのアクセス方法
- これまた[]を使う
- 列ごと、行ごとの表示も可
- 「-」で取り除いたやつを返すのはベクトルのときと一緒
> d[2,3] [1] 10 > d[2,] a b c 2 6 10 > d[,3] [1] 9 10 11 12 > d[c(-2,-4),] a b c [1,] 1 5 9 [2,] 3 7 11
行列の基本演算
- 行列作って、足し算
- 直感的
> a <- matrix(c(1,2,3,4),2,2,byrow=T) > b <- matrix(c(1,2,3,4),2,2,byrow=T) > a+b [,1] [,2] [1,] 2 4 [2,] 6 8
積がやっかい
- 「*」にしちゃうと積にならないよ
- とりあえず誰もが最初にはまるところ
> a*b [,1] [,2] [1,] 1 4 [2,] 9 16
積を求めたいときは「%*%」を使うべし
> a%*%b [,1] [,2] [1,] 7 10 [2,] 15 22
逆行列を求める
- solve関数
> solve(a) [,1] [,2] [1,] -2.0 1.0 [2,] 1.5 -0.5
行列式
- det関数
> det(a) [1] -2
固有値
- 簡単
- 取り出し方は後で説明
- リストでできる
> eigen(a) $values [1] 5.3722813 -0.3722813 $vectors [,1] [,2] [1,] -0.4159736 -0.8245648 [2,] -0.9093767 0.5657675
データフレーム
- 行列に数値以外のものを入れたテーブル形式のデータ型
例
- とりあえずデータフレームにいれたいベクトルを用意
> ID1 <- c(1,2,3,4,5) > VISIT1 <- c(10,20,30,10,50) > SEX1 <- c("F","M","M","F","F") > WEIGHT <- c(30,20,90,40,30)
データフレームを作る
- data.frame関数
> A <- data.frame(id=ID1,vit=VISIT1,sex=SEX1,w=WEIGHT) > A id vit sex w 1 1 10 F 30 2 2 20 M 20 3 3 30 M 90 4 4 10 F 40 5 5 50 F 30 > summary(A) id vit sex w Min. :1 Min. :10 F:3 Min. :20 1st Qu.:2 1st Qu.:10 M:2 1st Qu.:30 Median :3 Median :20 Median :30 Mean :3 Mean :24 Mean :42 3rd Qu.:4 3rd Qu.:30 3rd Qu.:40 Max. :5 Max. :50 Max. :90
リスト
- ベクトルや配列は似たようなデータ構造をまとめて束ねたようなもの
- リストは異なるデータ構造を束ねたもの
- いろんな種類のベクトルをまとめてもよし
- List in Listでも構わない
例
- ベクトルと文字列と行列を束ねてみる
> list(c(1,2,3,4),"Yasuhisa Yoshida",matrix(1:4,2,2)) [[1]] [1] 1 2 3 4 [[2]] [1] "Yasuhisa Yoshida" [[3]] [,1] [,2] [1,] 1 3 [2,] 2 4
リストへのアクセス
- ベクトルとはちょっと違う
- [[]]でアクセス
- []でもいいけど、返ってくる結果がリストになっていてちょっと複雑
- それ以降の要素についてはベクトルとかと同じ
> list <- list(c(1,2,3,4),"Yasuhisa Yoshida",matrix(1:4,2,2)) > list[[1]] [1] 1 2 3 4 > list[[2]] [1] "Yasuhisa Yoshida" > list[[3]] [,1] [,2] [1,] 1 3 [2,] 2 4 > list[[3]][1,] [1] 1 3
リストは結構難しい><
- 返ってきた結果が予想と違うこととかが結構ある
- 例:ベクトルだと思って処理しようとしたら、実はリストが返ってきててうまくいかない
- 対処法
- mode関数
- class関数
- データ構造が何かを教えてくれる関数
例
- 1列目の1番目の値を取ってきたい
- うまくいかない。。。
- うまくいかない理由をmode関数で調べる
> list[1] [[1]] [1] 1 2 3 4 > list[1][1] [[1]] [1] 1 2 3 4 > list[[1]] [1] 1 2 3 4 > list[[1]][1] [1] 1 > mode(list) [1] "list" > mode(list[[1]]) [1] "numeric" > mode(list[1]) [1] "list"
リストの要素には名前を付けることができる
- 数字で覚えるのは面倒
- 名前でアクセスできるようにしよう
- hashの"ような"もの
- 「$」でアクセスするよ
> list <- list(vec=c(1,2,3,4),name="Yasuhisa Yoshida",matrix=matrix(1:4,2,2)) > list $vec [1] 1 2 3 4 $name [1] "Yasuhisa Yoshida" $matrix [,1] [,2] [1,] 1 3 [2,] 2 4 > list$name [1] "Yasuhisa Yoshida" > list$matrix[2,2] [1] 4
Rでlistがどのように使われているか
- 回帰分析をRにやらせる
- 赤の線
plot(cars$dist,cars$speed) abline(lm(speed~dist,data=cars),col="red")
![Quartz 2 [*]](http://img.skitch.com/20090502-kfc2yws646cdjag6ftjssef457.jpg)
これの内容がどうなっているか
> summary(lm(speed~dist,data=cars)) Call: lm(formula = speed ~ dist, data = cars) Residuals: Min 1Q Median 3Q Max -7.5293 -2.1550 0.3615 2.4377 6.4179 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 8.28391 0.87438 9.474 1.44e-12 *** dist 0.16557 0.01749 9.464 1.49e-12 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 3.156 on 48 degrees of freedom Multiple R-squared: 0.6511, Adjusted R-squared: 0.6438 F-statistic: 89.57 on 1 and 48 DF, p-value: 1.490e-12
リストの中身を見る
- str関数
> str(summary(lm(speed~dist,data=cars))) List of 11 $ call : language lm(formula = speed ~ dist, data = cars) $ terms :Classes 'terms', 'formula' length 3 speed ~ dist .. ..- attr(*, "variables")= language list(speed, dist) .. ..- attr(*, "factors")= int [1:2, 1] 0 1 .. .. ..- attr(*, "dimnames")=List of 2 .. .. .. ..$ : chr [1:2] "speed" "dist" .. .. .. ..$ : chr "dist" .. ..- attr(*, "term.labels")= chr "dist" .. ..- attr(*, "order")= int 1 .. ..- attr(*, "intercept")= int 1 .. ..- attr(*, "response")= int 1 .. ..- attr(*, ".Environment")=<environment: R_GlobalEnv> .. ..- attr(*, "predvars")= language list(speed, dist) .. ..- attr(*, "dataClasses")= Named chr [1:2] "numeric" "numeric" .. .. ..- attr(*, "names")= chr [1:2] "speed" "dist" $ residuals : Named num [1:50] -4.62 -5.94 -1.95 -4.93 -2.93 ... ..- attr(*, "names")= chr [1:50] "1" "2" "3" "4" ... $ coefficients : num [1:2, 1:4] 8.2839 0.1656 0.8744 0.0175 9.474 ... ..- attr(*, "dimnames")=List of 2 .. ..$ : chr [1:2] "(Intercept)" "dist" .. ..$ : chr [1:4] "Estimate" "Std. Error" "t value" "Pr(>|t|)" $ aliased : Named logi [1:2] FALSE FALSE ..- attr(*, "names")= chr [1:2] "(Intercept)" "dist" $ sigma : num 3.16 $ df : int [1:3] 2 48 2 $ r.squared : num 0.651 $ adj.r.squared: num 0.644 $ fstatistic : Named num [1:3] 89.6 1 48 ..- attr(*, "names")= chr [1:3] "value" "numdf" "dendf" $ cov.unscaled : num [1:2, 1:2] 7.68e-02 -1.32e-03 -1.32e-03 3.07e-05 ..- attr(*, "dimnames")=List of 2 .. ..$ : chr [1:2] "(Intercept)" "dist" .. ..$ : chr [1:2] "(Intercept)" "dist" - attr(*, "class")= chr "summary.lm"
リストの要素を取得
- 「$」でアクセスする
> summary(lm(speed~dist,data=cars))$coefficients Estimate Std. Error t value Pr(>|t|) (Intercept) 8.2839056 0.87438449 9.473985 1.440974e-12 dist 0.1655676 0.01749448 9.463990 1.489836e-12
因子型
- factor型とも
irisのデータでやってみる
- あやめのデータ
- よく使われるデータ
- よい性質を持っているから
irisデータ
- それぞれ50個ずついるよ
> head(iris$Species) [1] setosa setosa setosa setosa setosa setosa Levels: setosa versicolor virginica > class(iris$Species) [1] "factor" > summary(iris$Species) setosa versicolor virginica 50 50 50
層別にSepal.Lengthの長さを調べてみる
- tapply(データ, 因子型のデータ, 関数)
> tapply(iris$Sepal.Length,iris$Species,mean) setosa versicolor virginica 5.006 5.936 6.588
ヒストグラムを書いてみよう
> library(lattice) > histogram(~Sepal.Length,data=iris)
できあがり
- 普通のヒストグラムと一緒じゃん
- 違うよ、全然違うよ
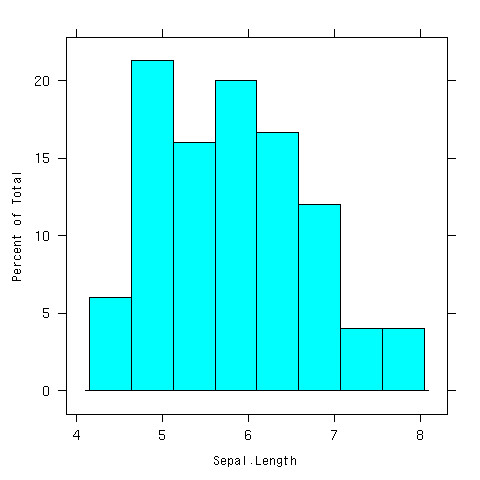
層別にヒスとグラムを書けるのがlatticeライブラリのhistgram
- 分布が違うね、とかいうことが分かる
> histogram(~Sepal.Length|Species,data=iris)
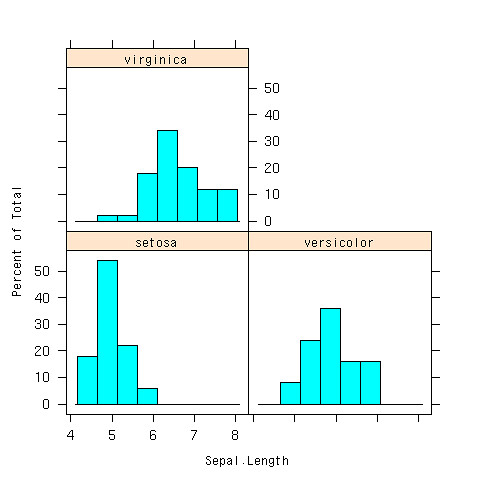
層別に分析するのはよく使う
- 顧客を色んな軸(性別、年齢、etc)で切って、データを分析しやすくする
- 主成分分析で次元削減した軸で、層別の分析etc
層別に統計量を出してくれるのがby関数
- 第一引数に求めたいデータ
- 第二引数に層別するもとのデータ
- 第三引数に求めたい統計量
- mean
- var
> by(iris$Sepal.Length,iris$Species,summary) INDICES: setosa Min. 1st Qu. Median Mean 3rd Qu. Max. 4.300 4.800 5.000 5.006 5.200 5.800 ------------------------------------------------------------ INDICES: versicolor Min. 1st Qu. Median Mean 3rd Qu. Max. 4.900 5.600 5.900 5.936 6.300 7.000 ------------------------------------------------------------ INDICES: virginica Min. 1st Qu. Median Mean 3rd Qu. Max. 4.900 6.225 6.500 6.588 6.900 7.900
行列やデータフレームを持ってくることもできる
- それぞれの列に対して層別された統計量を求める
> by(x[1:4],iris$Species,mean) iris$Species: setosa Sepal.Length Sepal.Width Petal.Length Petal.Width 5.006 3.428 1.462 0.246 ------------------------------------------------------------ iris$Species: versicolor Sepal.Length Sepal.Width Petal.Length Petal.Width 5.936 2.770 4.260 1.326 ------------------------------------------------------------ iris$Species: virginica Sepal.Length Sepal.Width Petal.Length Petal.Width 6.588 2.974 5.552 2.026
層別で頻度を集計する
- 条件を付けたりすることができる
> xtabs(~Species,data=iris,Sepal.Width>3) Species setosa versicolor virginica 42 8 17
散布図を層別で書いてみる
- 色分け
- 他にもいろいろオプションはあるよ
- ヘルプで見てね
> xyplot(Sepal.Length~Sepal.Width,data=iris,col=as.integer(iris$Species))
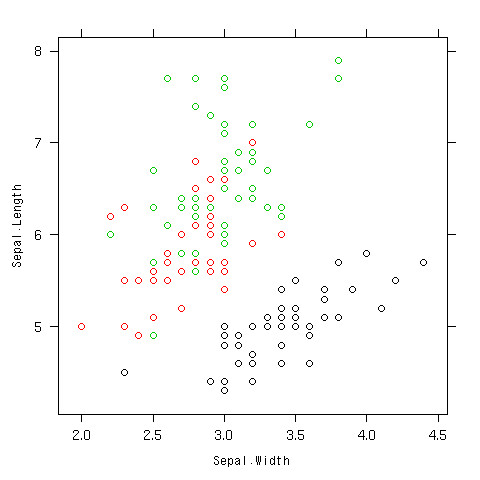
配布する資料が白黒だったら。。。
- そもそも散布図を3つ書けばよい
- 「|」の後に因子データを持ってくる
> xyplot(Sepal.Length~Sepal.Width|Species,data=iris)
できあがり
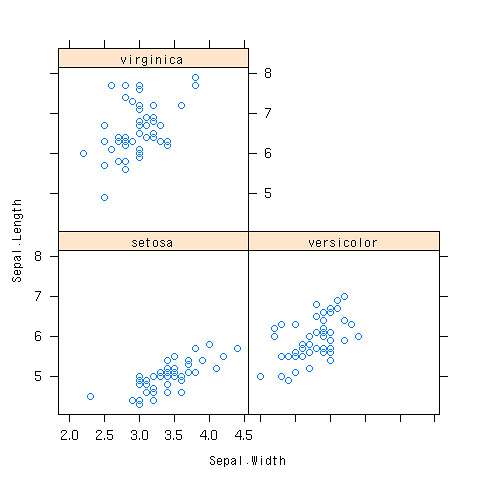

データ型の話はこの辺でとりあえず
apply familyの紹介
まとめ
- Rらしいコードを書くならapply family
- ベクトル、行列、データフレーム、リストに対して何か作用させるようなもの
- applyとtapplyは覚えて帰って損ないよ!!
apply familyって?
- lispのapplyのようなもの
- Rを使いこなす上では割けては通れない関数群
- Rはインタプリタ的なものなので、for文をそのまま回すと遅いことがある
- ベクトルを中心に考えるRとしては、Rらしいコードが書ける
で、applyファミリーって何?
- ベクトル、行列、データフレーム、リストに対して何か作用させるようなもの
例で説明
apply
- 行や列に対していっぺんに何かを作用させる
- 意味分かんない
- 例
> cars > mean(cars$speed) [1] 15.4 > mean(cars$dist) [1] 42.98
一つ一つめんどくさい
- この例ならsummary(cars)とかでできる
- 自分で作った関数とかsummaryがやってくれないやつを一辺にやりたい
- 例えば、自分で平均と標準偏差を返す関数を作ったとか
- そういう時にapply関数
実例
- 第一引数にデータフレーム
- 行列でもいい
- 第二引数は1か2
- 1は行
- 2は列
> apply(cars,2,mean) speed dist 15.40 42.98
lapplyとsapply
- 本質的には同じような働きをする関数
- 返す結果がリストか、ベクトル(行列)かという違いくらい
lapply
- リストに対して、ある関数をそれぞれ適用させるための関数
- データフレームっぽいのならapplyでいい
- 長さが整っていないものならlapplyかsapplyを使いましょう
- lapplyは返す結果がlist
> a <- 1:10 > b <- letters[1:26] > x <- list(a,b) > lapply(x,summary) [[1]] Min. 1st Qu. Median Mean 3rd Qu. Max. 1.00 3.25 5.50 5.50 7.75 10.00 [[2]] Length Class Mode 26 character character
sapply
- lapplyの返す結果がベクトルのやつ
- 返ってきた結果を使いまわすんだったら、こっちのほうが使い易いかもしれない
> x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,TRUE,FALSE)) > sapply(x, mean) a beta logic 5.500000 4.535125 0.500000
mapply
- (複数個の)ベクトルのそれぞれの要素をある関数に適用させることができる関数
- RubyやPerlのmapと思ってもらえばいいです
> mapply(function(x,y){x+y},1:10,11:20) [1] 12 14 16 18 20 22 24 26 28 30 > mapply(function(x){paste("R:",x,sep="")},1:10) [1] "R:1" "R:2" "R:3" "R:4" "R:5" "R:6" "R:7" "R:8" "R:9" "R:10"
mapplyを使わないでやることもできる
- ベクトル中心の考え方
> paste("R:",1:10,sep="") [1] "R:1" "R:2" "R:3" "R:4" "R:5" "R:6" "R:7" "R:8" "R:9" "R:10"
tapply
- 因子とか層別で分析したいときに重宝する関数
- こいつはapplyとtapplyくらいは覚えて帰って損しないと思うよ
> library(MASS) > attach(quine) > tapply(Days,Age,mean) F0 F1 F2 F3 14.85185 11.15217 21.05000 19.60606 > tapply(Days,list(Sex,Age),mean) F0 F1 F2 F3 F 18.70000 12.96875 18.42105 14.00000 M 12.58824 7.00000 23.42857 27.21429 > tapply(Days,list(Sex,Age),mean) F0 F1 F2 F3 F 18.70000 12.96875 18.42105 14.00000 M 12.58824 7.00000 23.42857 27.21429
まとめ
- Rらしいコードを書くならapply family
- ベクトル、行列、データフレーム、リストに対して何か作用させるようなもの
- applyとtapplyは覚えて帰って損ないよ!!
全体でのまとめ
- 自己紹介
- Tsukuba.Rについて
- 事前調査
- Rのぐぐり方、効率がよい(と思われる)勉強の仕方
- Rのデータ構造とそれに関する関数
- ベクトル、行列、データフレーム、リスト
- 因子型、層別分析
- apply family