12月は全然R勉強会とかやらなかったわけですが、資料は作ってました。お蔵行きにするのもあれなので、公開しておこうと思います。
話題的にはapplyファミリーとか、層別分析の仕方、層別分析に持っていくまでのデータ加工の仕方、などを説明してます。勉強会で使う用の資料、ということでちょっとWebで公開するには分かりづらい点があるかもしれませんが、その辺は勘弁を。
扱うトピック
- いろいろやります
- 分析手法とかじゃなくって、Rを使っていてかゆいところに手が届く、的なところを目指してやります
- 「ああ、こういうこともあるのね」くらいで大丈夫かと思います
- てか、俺も全部使いこなせるわけじゃ(ry
applyファミリー
- Rを使いこなす上では割けては通れない関数群
- Rはインタプリタ的なものなので、for文をそのまま回すと遅いことがある
- そういうときに使うと実効速度を早くすることができるよ、っていう話
- ただし、本質的にfor文が必要とされるところではfor文を回しましょう
で、applyファミリーって何よ?
- ベクトル、行列、データフレーム、リストとかに対して何か作用させるようなもの
- ベクトル、行列、データフレーム、リストって何か覚えてますか?
- 覚えてない人はR勉強会第二回でやっているので後で見ておいてください
apply
- 行や列に対していっぺんに何かを作用させる
- 意味分かんない
- 例
> cars > mean(cars$speed) [1] 15.4 > mean(cars$dist) [1] 42.98
一つ一つめんどくさい
- この例ならsummary(cars)とかでできる
- 自分で作った関数とかsummaryがやってくれないやつを一辺にやりたい
- 例えば、自分で平均と標準偏差を返す関数を作ったとか
- そういう時にapply関数
実例
- 第一引数にデータフレーム
- 行列でもいいかな
- 第二引数は1か2
- マージンとか呼ぶらしい
- 1は行
- 2は列
- c(1,2)なんてこともできるらしい
- 少なくとも、俺はあんまり使わない*1
> apply(cars,2,mean) speed dist 15.40 42.98
sweep
- applyと一緒に使うことが多い
使いたい場面
- 平均値からさっ引いたものを計算したい
- インデックスが大きくなれば、どんどん平均値から離れていくのか?など
- 分散の不均一性など
> sweep(cars,2,apply(cars,2,mean))
mapply
- (複数個の)ベクトルのそれぞれの要素をある関数に適用させることができる関数
- イメージ
- 図示します
> x <- 1:9 > y <- 10:18 > mapply(function(x,y){x+y},x,y) [1] 11 13 15 17 19 21 23 25 27
lapplyとsapply
- 本質的には同じような働きをする関数
- 返す結果がリストか、ベクトル(行列)かという違いくらい
lapply
- リストに対して、ある関数をそれぞれ適用させるための関数
- データフレームっぽいのならapplyでいい
- 長さが整っていないものならlapplyかsapplyを使いましょう
> a <- 1:10 > b <- letters[1:26] > x <- list(a,b) > lapply(x,summary) [[1]] Min. 1st Qu. Median Mean 3rd Qu. Max. 1.00 3.25 5.50 5.50 7.75 10.00 [[2]] Length Class Mode 26 character character
sapply
- lapplyの返す結果がベクトルのやつ
- 返ってきた結果を使いまわすんだったら、こっちのほうが使い易いかもしれない
> x <- list(a = 1:10, beta = exp(-3:3), logic = c(TRUE,FALSE,TRUE,FALSE)) > sapply(x, mean) a beta logic 5.500000 4.535125 0.500000
tapply
- 因子とか層別で分析したいときに重宝する関数
- こいつはapplyとtapplyくらいは覚えて帰って損しないと思うよ
> library(MASS) > attach(quine) > tapply(Days,Age,mean) F0 F1 F2 F3 14.85185 11.15217 21.05000 19.60606 > tapply(Days,list(Sex,Age),mean) F0 F1 F2 F3 F 18.70000 12.96875 18.42105 14.00000 M 12.58824 7.00000 23.42857 27.21429 > tapply(Days,list(Sex,Age),mean) F0 F1 F2 F3 F 18.70000 12.96875 18.42105 14.00000 M 12.58824 7.00000 23.42857 27.21429
練習問題
- アクセスログのデータ
- おいらのブログのアクセスログ
- 入ってるデータ
- ユニークアクセス数
- 月
- 曜日
- とりあえずコピペをよろしく
- 何かLとかついてるけど、あんまり影響ないので気にしないで
count <- structure(list(day = c(1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L, 31L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L, 15L, 16L, 17L, 18L, 19L, 20L, 21L, 22L, 23L, 24L, 25L, 26L, 27L, 28L, 29L, 30L), month = c(1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 2L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 3L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 4L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 5L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 6L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 7L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 8L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 9L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 10L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L, 11L), week = c(1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L, 6L, 0L, 1L, 2L, 3L, 4L, 5L), count = c(15L, 38L, 55L, 35L, 74L, 68L, 39L, 32L, 55L, 66L, 41L, 56L, 39L, 51L, 64L, 60L, 83L, 39L, 65L, 46L, 74L, 92L, 52L, 50L, 65L, 29L, 40L, 35L, 69L, 56L, 92L, 94L, 65L, 27L, 37L, 46L, 51L, 35L, 43L, 48L, 36L, 36L, 68L, 128L, 45L, 52L, 32L, 23L, 45L, 69L, 64L, 34L, 21L, 35L, 55L, 75L, 61L, 111L, 59L, 57L, 38L, 45L, 65L, 62L, 42L, 65L, 44L, 47L, 51L, 25L, 85L, 50L, 51L, 163L, 84L, 79L, 76L, 50L, 78L, 59L, 97L, 110L, 42L, 81L, 56L, 47L, 63L, 46L, 32L, 55L, 47L, 45L, 34L, 51L, 21L, 29L, 31L, 40L, 41L, 25L, 63L, 42L, 46L, 30L, 88L, 121L, 109L, 65L, 53L, 85L, 63L, 68L, 116L, 80L, 57L, 58L, 47L, 35L, 51L, 41L, 42L, 48L, 56L, 20L, 35L, 24L, 57L, 39L, 80L, 99L, 59L, 45L, 52L, 167L, 136L, 135L, 95L, 80L, 56L, 105L, 124L, 75L, 77L, 68L, 76L, 72L, 89L, 133L, 110L, 129L, 90L, 89L, 95L, 94L, 114L, 99L, 123L, 94L, 92L, 81L, 78L, 89L, 70L, 105L, 102L, 71L, 74L, 82L, 102L, 93L, 87L, 69L, 72L, 55L, 56L, 54L, 40L, 66L, 59L, 83L, 60L, 68L, 60L, 56L, 81L, 75L, 79L, 62L, 48L, 84L, 99L, 76L, 100L, 97L, 53L, 85L, 77L, 107L, 88L, 71L, 52L, 77L, 58L, 114L, 61L, 78L, 56L, 41L, 35L, 67L, 56L, 71L, 70L, 44L, 43L, 49L, 737L, 952L, 116L, 88L, 89L, 76L, 69L, 54L, 66L, 53L, 62L, 70L, 53L, 56L, 56L, 99L, 71L, 42L, 50L, 65L, 53L, 78L, 184L, 126L, 114L, 68L, 91L, 59L, 61L, 91L, 69L, 110L, 58L, 71L, 59L, 72L, 108L, 96L, 85L, 97L, 106L, 112L, 73L, 191L, 128L, 102L, 116L, 81L, 77L, 96L, 105L, 112L, 88L, 101L, 94L, 42L, 55L, 96L, 111L, 115L, 92L, 92L, 103L, 86L, 110L, 141L, 117L, 97L, 74L, 79L, 84L, 142L, 144L, 100L, 110L, 99L, 80L, 86L, 100L, 119L, 111L, 117L, 90L, 93L, 67L, 143L, 131L, 119L, 103L, 90L, 55L, 108L, 119L, 94L, 84L, 99L, 108L, 68L, 91L, 133L, 128L, 105L, 143L, 212L, 127L, 136L, 228L, 160L, 145L, 143L, 119L, 114L, 128L, 181L, 128L, 170L, 192L, 104L)), .Names = c("day", "month", "week", "count"), row.names = c(NA, -334L), class = "data.frame")
問題
- 以下のことを調べたい
- ユニークアクセス数と月の間の関係
- ユニークアクセス数と曜日の間の関係
- ちなみに調べるとこんな感じのことが分かるよ
月ごとの平均の推移
- 8月がいっぱい来たときがあるので、平均が引っ張られてる
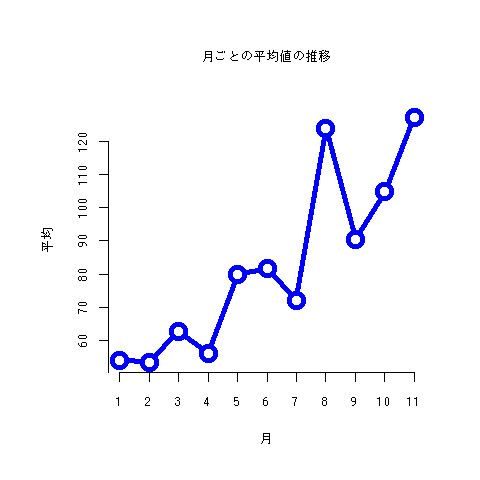
曜日ごとの平均の推移
- 周期性も見たい

ヒント
- applyファミリーのどれを使えばいいかを考えましょう
- グラフにするまでいけなくてもいいけど、いける人はいきましょう
- 曜日のところを数字じゃなくって、「月、火、…」とするにはどうすればいいでしょうか??
正解
- tapplyでした
- もっと詳しい調査はこの辺でやってるので興味あるひとはどうぞ
png("month_mean.png") par(mar=c(6,6,6,3)) plot(tapply(count$count,count$month,mean),pch=21,type="b",xlab="月",ylab="平均",main="月ごとの平均値の推移",axes=F,lwd=5,cex=2,lty=1,col=4) axis(1,1:11,1:11,) axis(2,seq(40,120,by=10)) dev.off() week <- c("日","月","火","水","木","金","土") png("week_mean.png") par(mar=c(6,6,6,3)) plot(tapply(count$count,count$week,mean),pch=21,type="b",xlab="曜日",ylab="平均",main="曜日の平均値の推移",axes=F,lwd=5,cex=2,lty=1,col=4) axis(1,1:7,week,) axis(2,seq(40,120,by=10)) dev.off()
irisデータ
- それぞれ50個ずついるよ
> summary(iris$Species) setosa versicolor virginica 50 50 50
ヒストグラムを書いてみよう
> library(lattice) > histogram(~Sepal.Length,data=iris)
できあがり
- 普通のヒストグラムと一緒じゃん
- 違うよ、全然違うよ
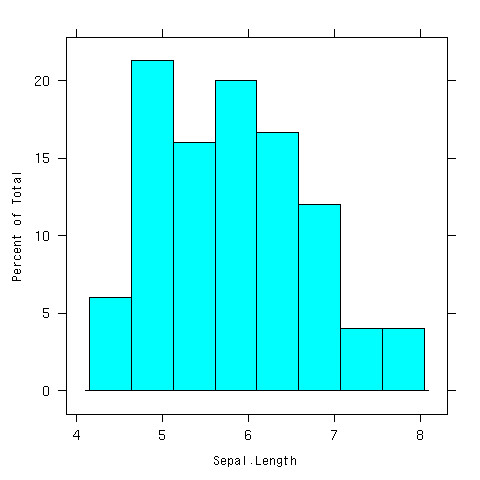
層別にヒスとグラムを書けるのがlatticeライブラリのhistgram
- 分布が違うね、とかいうことが分かる
> histogram(~Sepal.Length|Species,data=iris)
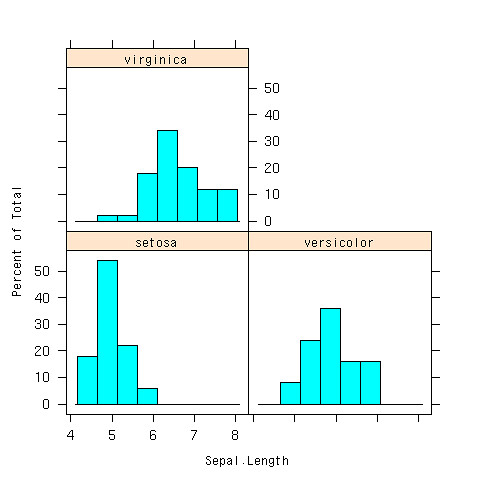
層別に統計量を出してくれるのがby関数
- 第一引数に求めたいデータ
- 第二引数に層別するもとのデータ
- 第三引数に求めたい統計量
- mean
- var
> by(iris$Sepal.Length,iris$Species,summary) INDICES: setosa Min. 1st Qu. Median Mean 3rd Qu. Max. 4.300 4.800 5.000 5.006 5.200 5.800 ------------------------------------------------------------ INDICES: versicolor Min. 1st Qu. Median Mean 3rd Qu. Max. 4.900 5.600 5.900 5.936 6.300 7.000 ------------------------------------------------------------ INDICES: virginica Min. 1st Qu. Median Mean 3rd Qu. Max. 4.900 6.225 6.500 6.588 6.900 7.900
行列やデータフレームを持ってくることもできる
- それぞれの列に対して層別された統計量を求める
> by(x[1:4],iris$Species,mean) iris$Species: setosa Sepal.Length Sepal.Width Petal.Length Petal.Width 5.006 3.428 1.462 0.246 ------------------------------------------------------------ iris$Species: versicolor Sepal.Length Sepal.Width Petal.Length Petal.Width 5.936 2.770 4.260 1.326 ------------------------------------------------------------ iris$Species: virginica Sepal.Length Sepal.Width Petal.Length Petal.Width 6.588 2.974 5.552 2.026
層別で頻度を集計する
- 条件を付けたりすることができる
- 異常値っぽいのをカウントするときとかに使える?かも
> xtabs(~Species,data=iris,Sepal.Width>3) Species setosa versicolor virginica 42 8 17
散布図を層別で書いてみる
- 色分け
- 他にもいろいろオプションはあるよ
- ヘルプで見てね
> xyplot(Sepal.Length~Sepal.Width,data=iris,col=as.integer(iris$Species))
できあがり
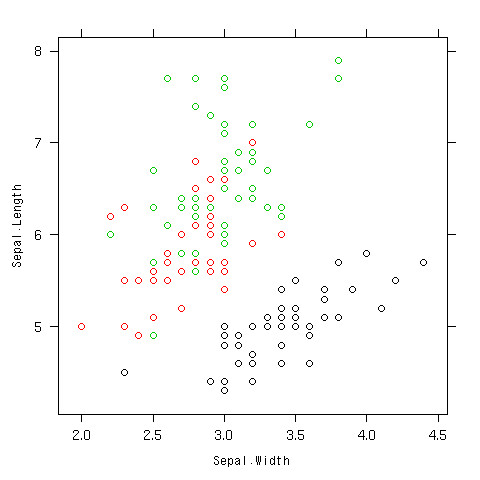
配布する資料が白黒だったら。。。
- そもそも散布図を3つ書けばよい
- 「|」の後に因子データを持ってくる
> xyplot(Sepal.Length~Sepal.Width|Species,data=iris)
できあがり
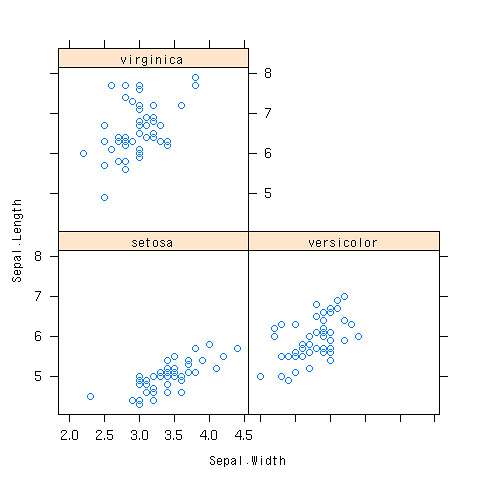
irisのデータで相関係数行列を求めよう
- もう分かるよね
- 5列目は因子だから要らない
> cor(iris[1:4]) Sepal.Length Sepal.Width Petal.Length Petal.Width Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411 Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259 Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654 Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
別解
- 「[-5]」と書くと5列目を抜いた行列を返してくれるよ
> cor(iris[-5]) Sepal.Length Sepal.Width Petal.Length Petal.Width Sepal.Length 1.0000000 -0.1175698 0.8717538 0.8179411 Sepal.Width -0.1175698 1.0000000 -0.4284401 -0.3661259 Petal.Length 0.8717538 -0.4284401 1.0000000 0.9628654 Petal.Width 0.8179411 -0.3661259 0.9628654 1.0000000
相関係数行列の問題
- 数字が多くて分かりづらい
- 例:10×10の相関係数行列
- どこが相関係数が大きいか知りたい
- グラフィックに表そう
相関係数行列の見た目を変える
- symnum関数
- とりあえずわけも分からず、下のをコピペで動かしてみよう
> symnum(abs(cor(iris[-5])),cutpoint=c(0,0.2,0.4,0.6,0.8,1),symbols=c(" ",".","-","+","**")) S.L S.W P.L P.W Sepal.Length ** ** ** Sepal.Width ** - . Petal.Length ** - ** ** Petal.Width ** . ** ** attr(,"legend") [1] 0 ' ' 0.2 '.' 0.4 '-' 0.6 '+' 0.8 '**' 1
symnum関数は便利!!
- 数値データを区間データに分ける
- 例えば、クロス分析
- 数字が都道府県と対応
- 関東地方とかで分ける
- プログラムでも書けるけど、それだけのために書くのって結構面倒
- てか、ifの分岐がたくさんできてあんまりうれしくないですね。。。
- Rでできないの?
- できます!!
symnum関数で数値データを区間データに分ける
> symnum(iris$Sepal.Length,cutpoint=c(4,4.5,5,5.5,6,6.5,7,7.5,8),symbols=c("4.0~4.5","4.5~5","5~.5.5","5.5~6","6~6.5","6.5~7","7~7.5","7.5~8")) [1] 5~.5.5 4.5~5 4.5~5 4.5~5 4.5~5 5~.5.5 4.5~5 4.5~5 4.0~4.5 [10] 4.5~5 5~.5.5 4.5~5 4.5~5 4.0~4.5 5.5~6 5.5~6 5~.5.5 5~.5.5 [19] 5.5~6 5~.5.5 5~.5.5 5~.5.5 4.5~5 5~.5.5 4.5~5 4.5~5 4.5~5 [28] 5~.5.5 5~.5.5 4.5~5 4.5~5 5~.5.5 5~.5.5 5~.5.5 4.5~5 4.5~5 [37] 5~.5.5 4.5~5 4.0~4.5 5~.5.5 4.5~5 4.0~4.5 4.0~4.5 4.5~5 5~.5.5 [46] 4.5~5 5~.5.5 4.5~5 5~.5.5 4.5~5 6.5~7 6~6.5 6.5~7 5~.5.5 [55] 6~6.5 5.5~6 6~6.5 4.5~5 6.5~7 5~.5.5 4.5~5 5.5~6 5.5~6 [64] 6~6.5 5.5~6 6.5~7 5.5~6 5.5~6 6~6.5 5.5~6 5.5~6 6~6.5 [73] 6~6.5 6~6.5 6~6.5 6.5~7 6.5~7 6.5~7 5.5~6 5.5~6 5~.5.5 [82] 5~.5.5 5.5~6 5.5~6 5~.5.5 5.5~6 6.5~7 6~6.5 5.5~6 5~.5.5 [91] 5~.5.5 6~6.5 5.5~6 4.5~5 5.5~6 5.5~6 5.5~6 6~6.5 5~.5.5 [100] 5.5~6 6~6.5 5.5~6 7~7.5 6~6.5 6~6.5 7.5~8 4.5~5 7~7.5 [109] 6.5~7 7~7.5 6~6.5 6~6.5 6.5~7 5.5~6 5.5~6 6~6.5 6~6.5 [118] 7.5~8 7.5~8 5.5~6 6.5~7 5.5~6 7.5~8 6~6.5 6.5~7 7~7.5 [127] 6~6.5 6~6.5 6~6.5 7~7.5 7~7.5 7.5~8 6~6.5 6~6.5 6~6.5 [136] 7.5~8 6~6.5 6~6.5 5.5~6 6.5~7 6.5~7 6.5~7 5.5~6 6.5~7 [145] 6.5~7 6.5~7 6~6.5 6~6.5 6~6.5 5.5~6 attr(,"legend") [1] 4 '4.0~4.5' 4.5 '4.5~5' 5 '5~.5.5' 5.5 '5.5~6' 6 '6~6.5' 6.5 '6.5~7' 7 '7~7.5' 7.5 '7.5~8' 8
元のデータはこれ
- さっきのと対応させてみてね
- 以下、未満などなど
> iris$Sepal.Length [1] 5.1 4.9 4.7 4.6 5.0 5.4 4.6 5.0 4.4 4.9 5.4 4.8 4.8 4.3 5.8 5.7 5.4 5.1 [19] 5.7 5.1 5.4 5.1 4.6 5.1 4.8 5.0 5.0 5.2 5.2 4.7 4.8 5.4 5.2 5.5 4.9 5.0 [37] 5.5 4.9 4.4 5.1 5.0 4.5 4.4 5.0 5.1 4.8 5.1 4.6 5.3 5.0 7.0 6.4 6.9 5.5 [55] 6.5 5.7 6.3 4.9 6.6 5.2 5.0 5.9 6.0 6.1 5.6 6.7 5.6 5.8 6.2 5.6 5.9 6.1 [73] 6.3 6.1 6.4 6.6 6.8 6.7 6.0 5.7 5.5 5.5 5.8 6.0 5.4 6.0 6.7 6.3 5.6 5.5 [91] 5.5 6.1 5.8 5.0 5.6 5.7 5.7 6.2 5.1 5.7 6.3 5.8 7.1 6.3 6.5 7.6 4.9 7.3 [109] 6.7 7.2 6.5 6.4 6.8 5.7 5.8 6.4 6.5 7.7 7.7 6.0 6.9 5.6 7.7 6.3 6.7 7.2 [127] 6.2 6.1 6.4 7.2 7.4 7.9 6.4 6.3 6.1 7.7 6.3 6.4 6.0 6.9 6.7 6.9 5.8 6.8 [145] 6.7 6.7 6.3 6.5 6.2 5.9
symnum関数の戻り値を見てみる
- mode関数はオブジェクトが何者かを示す
- listとかarrayという具合に教えてくれる
- 今回はキャラクター型らしい
> kukan<-symnum(iris$Sepal.Length,cutpoint=c(4,4.5,5,5.5,6,6.5,7,7.5,8),symbols=c("4.0~4.5","4.5~5","5~.5.5","5.5~6","6~6.5","6.5~7","7~7.5","7.5~8")) > mode(kukan) [1] "character"
因子型
- 層別分析をするために必要なデータの型はfactor(因子)型
- キャラクター型から因子型への変換
- これをirisのデータにくっつけるなりをすれば層別分析ができるようになる
> factor(kukan) [1] 5~.5.5 4.5~5 4.5~5 4.5~5 4.5~5 5~.5.5 4.5~5 4.5~5 4.0~4.5 [10] 4.5~5 5~.5.5 4.5~5 4.5~5 4.0~4.5 5.5~6 5.5~6 5~.5.5 5~.5.5 [19] 5.5~6 5~.5.5 5~.5.5 5~.5.5 4.5~5 5~.5.5 4.5~5 4.5~5 4.5~5 [28] 5~.5.5 5~.5.5 4.5~5 4.5~5 5~.5.5 5~.5.5 5~.5.5 4.5~5 4.5~5 [37] 5~.5.5 4.5~5 4.0~4.5 5~.5.5 4.5~5 4.0~4.5 4.0~4.5 4.5~5 5~.5.5 [46] 4.5~5 5~.5.5 4.5~5 5~.5.5 4.5~5 6.5~7 6~6.5 6.5~7 5~.5.5 [55] 6~6.5 5.5~6 6~6.5 4.5~5 6.5~7 5~.5.5 4.5~5 5.5~6 5.5~6 [64] 6~6.5 5.5~6 6.5~7 5.5~6 5.5~6 6~6.5 5.5~6 5.5~6 6~6.5 [73] 6~6.5 6~6.5 6~6.5 6.5~7 6.5~7 6.5~7 5.5~6 5.5~6 5~.5.5 [82] 5~.5.5 5.5~6 5.5~6 5~.5.5 5.5~6 6.5~7 6~6.5 5.5~6 5~.5.5 [91] 5~.5.5 6~6.5 5.5~6 4.5~5 5.5~6 5.5~6 5.5~6 6~6.5 5~.5.5 [100] 5.5~6 6~6.5 5.5~6 7~7.5 6~6.5 6~6.5 7.5~8 4.5~5 7~7.5 [109] 6.5~7 7~7.5 6~6.5 6~6.5 6.5~7 5.5~6 5.5~6 6~6.5 6~6.5 [118] 7.5~8 7.5~8 5.5~6 6.5~7 5.5~6 7.5~8 6~6.5 6.5~7 7~7.5 [127] 6~6.5 6~6.5 6~6.5 7~7.5 7~7.5 7.5~8 6~6.5 6~6.5 6~6.5 [136] 7.5~8 6~6.5 6~6.5 5.5~6 6.5~7 6.5~7 6.5~7 5.5~6 6.5~7 [145] 6.5~7 6.5~7 6~6.5 6~6.5 6~6.5 5.5~6 Levels: 4.0~4.5 4.5~5 5.5~6 5~.5.5 6.5~7 6~6.5 7.5~8 7~7.5
欠損値の取り扱い
> x <- c(1,3,2,1,NA,4) > y <- c(2,NA,3,2,5,4) > z <- c(5,3,2,3,2,1) > w <- cbind(x,y,z) > w x y z [1,] 1 2 5 [2,] 3 NA 3 [3,] 2 3 2 [4,] 1 2 3 [5,] NA 5 2 [6,] 4 4 1
NAがあるやつを全部抜く
- complete.cases関数
- 論理値のandを取る
> complete.cases(w) [1] TRUE FALSE TRUE TRUE FALSE TRUE > w[complete.cases(w),]
*1:使えこなせてないだけ?