データエンジニア系の勉強会で最近dbtがぱらぱらと話題に出てくるようになった & 4連休ということで、夏休みの自由研究がてらdbtを触ってみました。書いてる人のバックグラウンドは以下の通り。
- DWHやデータマートの構築のためのETLツールを模索中(特にTの部分)
- プライベートではDataformを使っている
- 前職でも仕事の一部で使っていた
- 定期バッチ処理はArgo Workflows on GKEでやっている
触ってみないと肌感とか自分で運用できるかのイメージが湧かないのでね。
Dataformとの比較
- メインの守備範囲はDataformとかなりオーバーラップ
- BigQueryなど強力なエンジンを背景に、SQLのみでTransformationを行なう
refを使ったデータ間の依存関係の表現やデータリネージ- データ品質(例: non nullとかuniquness)を担保するための機能をyamlやSQLなどで記述できる
- BigQueryに投げるSQLのテスト、mockを書くのは死ぬほどダルいけど、dataformやdbtでテストを書くのが今後スタンダードになっていくのかなー
- devやprodでアレコレ出し分け
- tableにしたり、viewにしたり、incrementalにテーブルを作ったり
- Dataformが強いと感じた部分
- 実際のクエリを走らせるためのWeb UIが用意されているので、エンジニアリングにそこまで強くない(あるいはエンジニアリングに強いが、工数がそこまで割けない)場合はかなり便利
- SQLに強い分析者にもちょっとした修正を頼めるイメージが持てる。画面上でブランチ切り替えて挙動を見ながら試行錯誤できるので、Lookerと感覚が近い
- dbtもcloud版だとほぼ同様のことができる?ここは試してはいない
- スケジューリングの機能も内包している
- cron形式やhourlyなどでSQLを定期実行できる
- 依存先も合わせて更新や特定のタグが付いているもののみを更新といったこともできる
- dbt(のcli)はスケジューリング機能は提供してない
- 実際のクエリを走らせるためのWeb UIが用意されているので、エンジニアリングにそこまで強くない(あるいはエンジニアリングに強いが、工数がそこまで割けない)場合はかなり便利
- dbtが強いと感じた部分
- Dataformよりも小さく切り出して、他のツールと組み合せやすい
- 例: データ品質の事前テスト(データレイクのfreshnessとか)が通った場合のみrunして、runが終わったらデータリネージを含むdocsを更新してslackに通知とか
- dbtは各パーツを切り出して、その他のワークフローエンジンと組み合わせやすい。Airflowとの組み合わせが人気っぽいけど、後述するようにArgo Workflowsでも全く問題なく使える
- コマンドの出力の結果をjsonで吐ける
- データリネージが見やすい
- 管理する対象が増えるとデータリネージの図が巨大になって見にくくなるが、dbtは色んな条件を書けるので関連するところだけ見るといったことが容易
- Slowly Changing Dimensionsに対応
- 状態を管理するカラムがあるが、変更の履歴テーブルが存在しない。分析では状態の変化も考慮したい...といった場合、Slowly Changing Dimensionsができると便利
- dbtの場合、snapshotという機能を使うと、Slowly Changing Dimensionsを手早く提供できる
- 細かい使い勝手はdbtのほうがよいなと感じた。Jinjaやマクロが使えるので、かなり強力
- Exposuresというものがあり、ダッシュボードやDWHの先で利用しているアプリケーションを含めてデータリネージを書くことができる
- Dataformよりも小さく切り出して、他のツールと組み合せやすい
ワークフローエンジンを自前で管理できる技術力や工数がある場合にはdbtは便利そう、そうでない場合はDataformのほうが便利そう、という巷で言われていることと大体同じ所感に行き着きました。エンジニア以外の人も修正する場合はDataformのほうがよさそうだが、dbt cloudだとのケースもカバーできそう。ただ、dbt cloudだと小回りが効くツール感が薄くなるというところがあり*1、何らかの割り切りが必要かなーと思いました。
細かいノウハウ
手元や本番環境での動作
手元で動かすのは本当に簡単。brewでinstallして、dbt initで生成されるテンプレートをちょっと修正すれば1時間もかからず試せる。
手元の場合はgcloud経由のOAuthだが、サーバーやコンテナ環境で動かす場合は当たり前だがサービスアカウントが必要になる。サービスアカウントのキーをそのままコンテナのimageに含めるのは論外として、secretで管理するのもダルい。自分はGKE上で動かすので、この辺りはWorkload Identityで解決させる。
ただ、dbtはサービスアカントのファイルを要求してくるので、ちょっと困った。GCPの場合はimpersonating-service-accountsというのがあるようで、これを使うと有効期限が短かいサービスアカウントのトークンを生成できる。
- Managing service account impersonation | Cloud IAM Documentation
- Creating short-lived service account credentials
この辺りのサービスアカウントの権限はTerraformだとこういう感じで書く。
resource "google_service_account" "dbt_runner_service_account" { account_id = "dbt-runner" display_name = "Service account for dbt" } resource "google_project_iam_member" "dbt_runner_roles" { for_each = toset([ "roles/bigquery.jobUser", "roles/bigquery.dataEditor", "roles/iam.serviceAccountTokenCreator", ]) role = each.key member = "serviceAccount:${google_service_account.dbt_runner_service_account.email}" } resource "google_service_account_iam_member" "dbt_wi_iam_binding" { service_account_id = google_service_account.dbt_runner_service_account.name member = "serviceAccount:my-project.svc.id.goog[dbt-runner-ns/dbt-runner-sa]" role = "roles/iam.workloadIdentityUser" }
dbtの設定ファイル(profiles.yml)ではこういう感じで書く。dbtを起動する際にdbt run --profiles-dir . --full-refresh --target localという具合にtargetを指定できて、環境毎に認証の方法やETLした後のデータを出力するBigQueryのデータセットを指定できる。
ml-news: target: local outputs: local: type: bigquery method: oauth project: ml-news dataset: test_test threads: 4 timeout_seconds: 300 location: asia-northeast1 priority: interactive retries: 1 prod: type: bigquery method: oauth project: ml-news dataset: test_test threads: 4 impersonate_service_account: dbt-runner@my-project.iam.gserviceaccount.com timeout_seconds: 300 location: asia-northeast1 priority: interactive retries: 1
Argo Workflowとの連携
Airflowとの組み合わせが人気っぽくて、Argo Workflowとの連携があまり見当らなかった。Argoでも特に問題なくできたので、やり方を書いておく。といってもdbtのimageをGCRにpushしておいて、あとはいつも通りArgo Workflowのテンプレートを書いていくだけ。
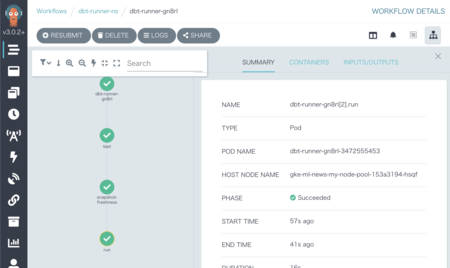
以下は条件を満たした時のみDWHを更新する例。
- 1: unique制約などのtestが通るか確認
- 品質が低い(正確性が低かったり一意性が満たされていない)データを誤ってユーザーに提供しない
- 2: データソースのfreshnessを確認
- 古いままだと更新する意味がない & データソースへのデータ転送が失敗している可能性に気付けるように
- 3: ここで初めてDWHの更新
apiVersion: argoproj.io/v1alpha1 kind: CronWorkflow metadata: name: {{ .Values.app.name }} namespace: {{ .Release.Namespace }} spec: schedule: "0 */12 * * *" concurrencyPolicy: "Replace" startingDeadlineSeconds: 0 workflowSpec: entrypoint: main serviceAccountName: {{ .Values.app.name }}-sa templates: - name: main steps: - - name: test template: dbt arguments: parameters: - name: command value: "dbt test --target prod" - - name: snapshot-freshness template: dbt arguments: parameters: - name: command value: "dbt source snapshot-freshness --target prod" - - name: run template: dbt arguments: parameters: - name: command value: "dbt run --target prod" - name: dbt inputs: parameters: - name: command container: image: gcr.io/{{ .Values.project.name }}/{{ .Values.app.name }}:latest command: - "/bin/sh" - "-c" args: - "{{ `{{inputs.parameters.command}}` }}"
環境によってDWHの提供するバージョンを差し替える
「新しいバージョンのテーブル(v0.0.2)をいきなりDWHにリリースすると事故るかもしれないので、開発環境だけv0.0.2にしておいて、本番環境はしばらくv0.0.1を提供したい」というDWHのバージョン管理を考えたい。
v0.0.1とv0.0.2はそれぞれ別のSQLで管理しつつ、ユーザー側に見せるテーブルを環境毎にテンプレートで差し替えるということができる(dbt run --target devの時のみviewは0.0.2を向く)。Jinjaが使えるので、まあまあ複雑なこともやれる(用法容量を守って適切に使いましょう)。
{{
config(
materialized = "view",
)
}}
SELECT
*
FROM
{% if target.name == 'dev' %}
{{ ref("dwh_v_0_0_2") }}
{% else %}
{{ ref("dhw_v_0_0_1") }}
{% endif %}
差し替えは結構使いどころがある。データが巨大で開発環境ではScan量を抑えたい or 実行時間を短かくしたい、といった場合に「開発環境だけ」直近のデータを使うとかJOINする前にLIMITで件数を少なめにしておくといったことができる。
DWHやデータマートの外の情報をデータリネージに加える
データ管理の仕事をしていると、大体自分の部署だけで済むことはあまりないです。例えば
- DWHで使ってるデータレイクのデータが古い、他チームがやってくれているデータ転送が遅延しているのでは...
- DWHのこのテーブルをリファクタリングしたい、事前に影響範囲を調べたいけど、これどこのチームが使ってるんだっけ
などなど。どのチームの誰に聞くといい、といった情報は暗黙知になりがちで、ともすると連絡が漏れて二次被害を出してしまうこともあります。
dbtではデータソース(データレイク)やExposures(ダッシュボードやnotebook、MLなどのアプリケーション)もデータリネージとして管理できます*2。dbtのいいところは依存関係だけでなくメタデータも管理してくれるところで、データマネジメントする人がいかにも管理したい*3情報を記録 & リネージの画面で確認できます。
- オーナーは誰か
- 管理しているダッシュボードやソースコードのURL
- maturity
- カラム変更する場合、highならば慎重に、lowならばがっと変えても大丈夫などの判断ができる
- その他メタデータ
- 生成のタイミング/場所、利用用途
- 関連するslackのチャンネル
既存のテーブルの取り込み(dbt-helper)
既存のデータレイクにあるテーブルをdbt内で呼び出す場合、source関数を使うことになります。dbtに取り込む場合、数が少なければ目視でポチポチ作ってもよいですが、数が多いと取り込むのも大変です。また、会社によって事情は違うと思いますが、DWHを管理している部署とデータレイクにデータを転送する部署が異なる場合があると思います。データを転送する部署がそのデータに一番詳しいので、メタデータを書いておいてくれる場合が多いと思いますが、sourceで管理しているファイルにもそのメタデータを自動で取り込みたくなります。
こういったケースで便利なのがdbt-helperです。以下のコマンドでBigQuery => dbtの取り込みができます。
% dbt-helper source importing --models_dir models \ --project my_company_project_a --project_alias project_a \ --dataset source__db --table '^user$'
コマンド実行後、models/project_a/source__db/bookmark/src_project_a__source__db__user.ymlに取り込んだ情報がyamlファイルに吐き出されます。取り込む対象のテーブルや正規表現で指定(指定しない場合はデータセットがimportされる)できます。--project_aliasのオプションは最初何だ?と思いましたが
- 開発用のプロジェクトなので
project-a-devというプロジェクトなのだが、名前としてはproject-aで認識させたい - project名に会社のprefixを付ける規則になっているが、長いのでprefixを省略させたい
といったケースに対応するためのものなのかなと思います*4。
また、初回のimport以降、データレイクのカラム名やカラムのdescription、labelなどが変更されることは容易に想像できます。BigQuery内の本物の定義とdbt中のsourceの定義が徐々にずれていくことは避けたいです。こうしたケースに対応できるようにupdate-dbt-sourceサブコマンドが用意されています。
% dbt-helper source update-dbt-source --models_dir models \ --source_path models/ml_news/source__db/bookmark/src_ml_news__source__db__bookmark.yml \ --vars_path dbt_project.yml
実行後、BigQuery側の情報が変わっているようであれば内容が変更されます。dbt側も情報書き換えているとどういう挙動をするのか気になるところですが、試してみたところ
- bq側のdescriptionが空なら、dbt側のdescriptionは生き残る
- bq側のdescriptionが空でないなら、dbt側のdescriptionは上書きされる
という挙動でした。dbt側に独自にdescriptionを書くことを許す設計になってますね。
vars_pathは最初何かよく分からなかったのですが、import時に書いたproject名とaliasの紐付けをするファイルを要求しているものでした。ファイル用意するのちょっとダルいので、コマンドライン引数で指定できるようになっていると嬉しい...。
projects: project-a-dev: "project-a"
プロジェクト構成
dbtのようなツールを導入する際はプロジェクト(ディレクトリ)構成が迷いどころになりがちです。コミュニティでの議論をベースにオススメの構成が紹介されています。
- How we structure our dbt projects - Modeling - dbt Discourse
- Should I have an organisation wide project (a monorepo) or should each work flow have their own? - Workflows - dbt Discourse
- パッケージに分割できるので、 モノレポじゃなくてもok
- Managing environments | dbt Docs
- targetで出し分けよう
- Best practices | dbt Docs
dbtの場合は特にnameが全体でユニークでないといけない(source/userとwarehouse/userだとuserが被っているのでダメ)、といった制約があります。この制約の中でうまくやるためには必然的に長い名前を付けないといけないですが、ファイル名などに統一感を持たせたいです。dbt-helperはmodelのscaffoldサブコマンドで統一した名前で{sql, yml, md}ファイルの雛形を作ってくれるので、個人的にはプロジェクト構成もこれに乗っかると楽かなぁと思いました。
ドキュメントの提供
dbtはdbt docs generateでドキュメントを生成して、dbt docs serveで手元から気軽にドキュメントを眺められます。APIサーバーというよりは静的ファイルが実態なので、(社内にIP制限などをした上で)S3やGCSにホスティングしてデータリネージなどを提供する形がよさそうです。

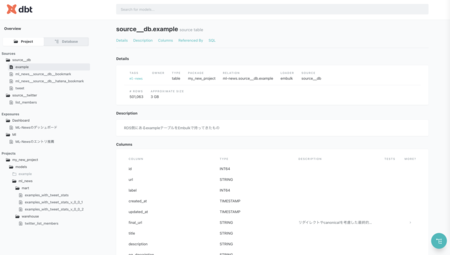
実際にドキュメントを触れるものが用意されているので、ぐりぐりと触ってみるのがよいと思います。
参考
主にUbieのデータエンジニアの方々とクラメソさんのエントリに助けられております、感謝〜。
- dbtとDataformを比較し、dbtを使うことにした – Attsun Blog
- bq_sushi #17 にて、「Data Management by dbt」という発表をしました。 – Attsun Blog
- さようなら、謎の数値ズレ。dbtを活用してデータ品質管理をはじめよう | by Sotaro Tanaka | Jun, 2021 | Medium
- データ変換処理をモダンな手法で開発できる「dbt」を使ってみた | DevelopersIO
- [dbt] 作成したデータモデルに対してテストを実行する | DevelopersIO
- [dbt] 作成するデータモデルに関するドキュメントを生成する | DevelopersIO
- データ変換処理をモダンな手法で開発できる「dbt」を使ってみた | DevelopersIO
- Data Lineage したい - satoshihirose.log
- 5 reasons why BigQuery users should use dbt | by Yu Ishikawa | Medium
- Toward Better Data Management on BigQuery with dbt | Mercari Engineering