基本的なことだけど、久しぶりにハマって2時間くらい溶かしてしまったので、自分用メモ。大体のことは以下の本に書いてある。

INとNULL
普通のプログラミング言語であれば、真偽値(BOOLEAN)はTRUE or FALSEの二通り。しかし、SQLの世界ではNULLが入ってくるため話がややこしくなる。いくつか例があるが、排中律が成立しないことが挙げられる。具体的なクエリとしては以下のようなもの。
SELECT 1 IN (1) AS a, 2 IN (1) AS b, 2 NOT IN (1) AS c, 1 IN (1, NULL) AS d, 2 IN (1, NULL) AS e, 2 NOT IN (1, NULL) AS f
eとfがやっかいで、同一の条件でINとNOT INを書いているので、どちらかがTRUEでどちらかがFALSEを期待してしまうが、結果はそんなことはなくてどちらもNULLになる。INを同値変換すると=とORを使った形(1 = 2 OR 1 = NULL)にできるが、変換された後ではIS NULLを使って比較をしていないため、こういったことが起きる。
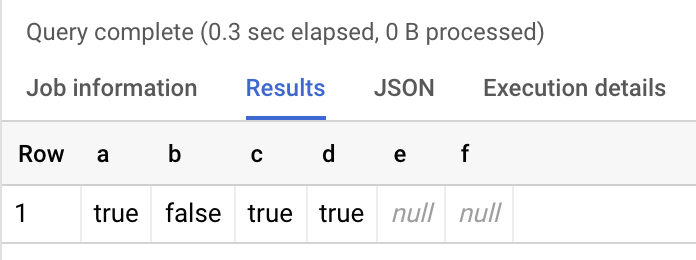
INに与えているリストの中に「一つでも」NULLが入っていると、結果がNULLになってしまう。この例は単純なのですぐに気付けるが、クエリをあれこれ組み合わせていると結構気付けなかったりする。
今回はまったケース
で、はまったケースがこちら(例なので、小さいサンプル)。でかいデータ(data)というものがあって、それぞれのカラムはNULLにならないと私は思っていた。このデータを適当にGROUP BYして、各行に対して文字列結合した結果にINを使った結果、TRUEでもFALSEでもなくNULLが登場してしまう。GROUP BYした結果が数万件単位あって、目視で見たところ異常なさそうと判断したのがよくなかった。
WITH data AS ( SELECT "a" AS a, "b" AS b, UNION ALL SELECT NULL AS a, "bb" AS b, UNION ALL SELECT "aa" AS a, NULL AS b, UNION ALL SELECT NULL AS a, NULL AS b, ), tmp AS ( SELECT a, b FROM data GROUP BY a, b ) SELECT "a:b" IN (SELECT a || ":" || b FROM tmp) AS x, "aa:b" IN (SELECT a || ":" || b FROM tmp) AS y, "aa:b" NOT IN (SELECT a || ":" || b FROM tmp) AS z

敗因としては元データにNULLがないと勝手に断定したことが原因で、これを防ぐためには
- 元データに
NULLが入るケースがあるか確認する- dbtのsourceのテストとかでも何でも
GROUP BYの条件にIS NOT NULLを忘れずに付けていくcoalesce関数などを使って、NULLの場合には他の値を入れていく
とかだろうか。
怖い例
古いテーブルを定期的に削除したいが、削除してはいけないテーブルがあって、それらはホワイトリスト形式で管理されている。削除候補対象に対してNOT IN ホワイトリストのようなことをやっていると、削除が全然されなかったり、(消してはいけないテーブルも含めて)全削除されてしまう、ということもあり得る。特に後者はやばいので、ホワイトリストの中にNULLが入っていないとか、削除候補と実際に削除する件数が一致していないか(全削除になっていないか)など、防衛的に振る舞うなどしたほうがよい*1。
所感
こういうのを人間がやるの、まあ間違えないほうが難しいよなって気がするので、型付きSQLみたいなのが出てきて欲しい。この結果はBOOLEANじゃなくてOPTIONAL<BOOLEAN>みたいなやつ。BigQueryだとカラムのSchema(モード)にNon-NULLを定義することはできるけど、SQLレベルでそれが判断したい。SQLはきっと10年後も生き残っているツールなんだろうけど、10年後も人間がこんなところで悩んでいる未来にはいたくないな...。調べればきっとすでにアイディアとしてはあるんだろうけど、まあ流行らなかったんだろうなぁ。以上、愚痴でした。
*1:やらかしたわけではないです