はてなグループ見てもらえばいいんだけど、せっかくはてな記法で書いたのでブログに転載しておこう。
R勉強会第一回
- Presented by 吉田康久
Rとは?
何それおいしいの?
どういうことができるか?
- 統計解析ソフト
- データ解析
- 医療関係
- 地図
- 最適化
なぜRを使うのか?
- 他にもいろいろあるよ!!
- Splus
- SPSS
- EXCEL
- SAS
Rは無料
- Splusは学校でしか使えない
いろいろできる
- さっき説明しました
クロスプラットフォーム
- Windows
- Unix
- MacOS
サポートの充実度
書籍

The R Tips―データ解析環境Rの基本技・グラフィックス活用集
- 作者: 舟尾暢男
- 出版社/メーカー: 九天社
- 発売日: 2005/02
- メディア: 単行本
- 購入: 3人 クリック: 20回
- この商品を含むブログ (34件) を見る
実践
やってみよう!!
Rの基本
- ベクトル
- c関数
使いかた
> c(1,2,3,4,5) [1] 1 2 3 4 5
[1,2,3,4,5]を生成。
- 注意
- 最初の「>」はコマンドのやつだから、一緒にコピペしないでね
- 次の行が出てくる結果
代入
xにベクトルを代入 > x<-c(1,2,3,4,5) > x=c(1,2,3,4,5)
- 代入の方法
- 「<-」
- 「=」
- まだまだあるよ
- ここでは「<-」で統一
代入されたものを見てみる
- 代入されたオブジェクトをそのままタイプ!!
> x [1] 1 2 3 4 5
- 結果を見てみたいとき
- 最初のうちはきちんとやった通りになっているか確認
Rで使えるデータ
> data()
- いろいろあるよ
- 今回は「trees」を使うよ
trees
- 何のデータ?
- これで説明出てくるよ!
> ?trees
- 概要
- Girth
- 木の回りの長さ
- Height
- 高さ
- Volume
- 体積
- Girth
ひとつずつ見たい
- さっきのでは、いっぺんにしか見れない
- 「Girth」だけ見たい
- 例えば
> trees[1]
- 「1」と「Girth」を覚えとかないと使えない
解決法
- これで何列目か覚えなくてもいいよ!!
> trees$Girth
- 毎回「trees」打つの面倒。。。
- 「attach」をやると「trees」を打つ必要はない
> attach(trees) > Girth
注意
- ぶつかったりすることがあるのでいらなくなったら「detach」しよう
> detach(trees) > Girth
データについて知ろう
- 平均
- 分散
- 分布
- 散布図
基本統計量
平均
> mean(Girth) [1] 13.24839
分散
> var(Girth) [1] 9.847914
注意
- 「var」で出すのは不偏分散だよ
- 標本分散が欲しいときには(n-1)/n倍しましょう
> 30/31**var(Girth) [1] 9.53024
今どうやってデータの数数えたの?
- 手で。。。
- ないない><
- 関数
> length(Girth) [1] 31
- だからさっきのも、これでできるよ
> (length(Girth)-1)/length(Girth)**var(Girth) [1] 9.53024
いろいろ知りたい
- 最大値、最小値
- 四分位点(quantile-range)
- それsummary関数でできるよ
> summary(Girth) Min. 1st Qu. Median Mean 3rd Qu. Max. 8.30 11.05 12.90 13.25 15.25 20.60
summary関数は便利
- treesのデータ、一回で全部知ることができるよ
> summary(trees) Girth Height Volume Min. : 8.30 Min. :63 Min. :10.20 1st Qu.:11.05 1st Qu.:72 1st Qu.:19.40 Median :12.90 Median :76 Median :24.20 Mean :13.25 Mean :76 Mean :30.17 3rd Qu.:15.25 3rd Qu.:80 3rd Qu.:37.30 Max. :20.60 Max. :87 Max. :77.00
分布
- ヒストグラムを書こう
> hist(Girth)
できあがり
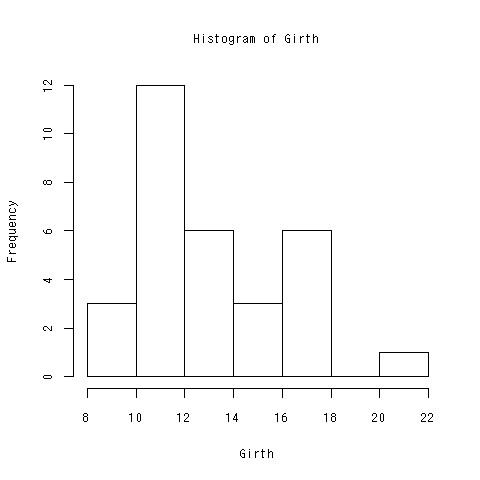
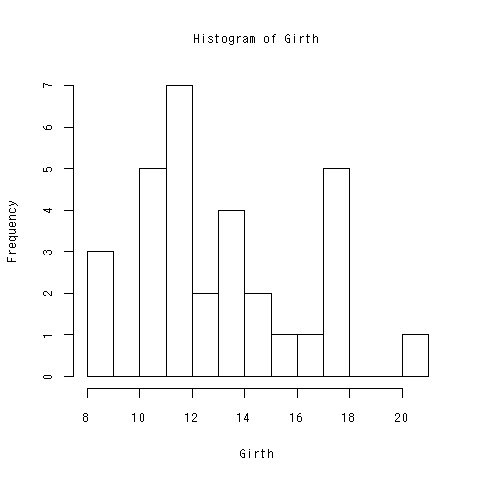
柱の数を変えたい
- 柱の数が問題になるときがある
- バイモーダルな分布
- 柱の数をいろいろ変えて見ていく必要がある
> hist(Girth,nclass=10)
できあがり
ヒストグラムの問題
- 柱の数
- 意図的に変えられる
- データの分布をきちんと読み取れないかもしれない
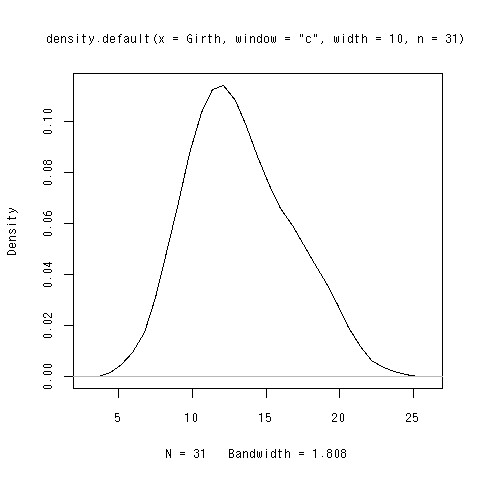
密度トレイス
- どういうのかは口頭で説明します
コマンド
- n:データの数
- window:たしこんでいく関数
- c:cos
- r:レンガみたいなやつ
- width:滑らかさの度合を調整するパラメータ。大きい程滑らか。
> plot(density(Girth,n=31,window="c",width=10))
できあがり
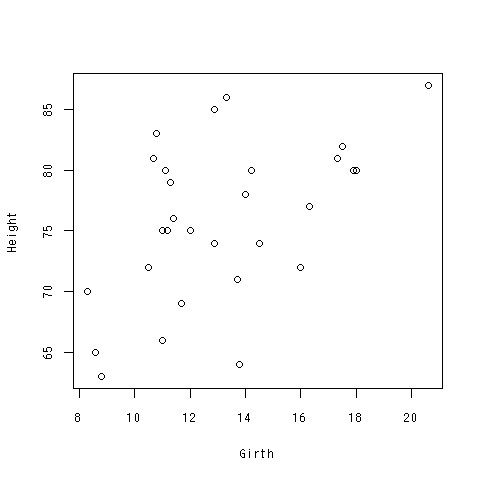
散布図
> plot(Girth,Height)
できあがり
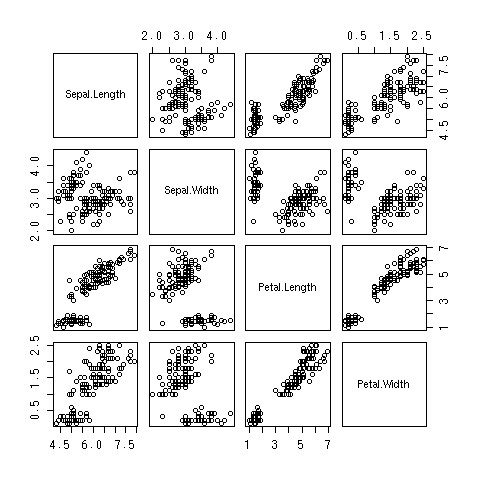
散布図行列
- ドラフツマンプロットとかとも言うらしい
- pairs関数
> pairs(iris[1:4])
- irisとか[1:4]はさておいて…
- 多変数での相関関係が見られるよ!!
できあがり
データの読み込み
- これまでは
- 自分でデータを作る
- 付属のデータで遊ぶ
- 外部のデータも利用できるようにしよう
- 今回はデータ解析で使ったものの一部を使用
- Consumers Report
- 車の価格など
データ
"car.name","low.price","low.displacement","low.horsepower","length" "Acura MDX",39995,3.7,300,191 "Acura RDX",32995,2.3,240,181 "Acura RL",45780,3.5,290,194 "Acura TL",33625,3.2,258,189 "Acura TSX",28090,2.4,205,183 "Audi A3",25340,2,200,169 "Audi A4",28240,2,200,180 "Audi A5",39000,3.2,265,182 "Audi A6",41950,3.2,255,194 "Audi A8",68900,4.2,354,204 "Audi Q7",39900,3.6,280,200 "Audi S4",47500,4.2,340,181 "Audi TT",34800,2,200,165 "BMW 3 Series",32400,3,230,178 "BMW 5 Series",43500,3,215,191 "BMW 6 Series",74700,4.8,360,190 "BMW 7 Series",75800,4.8,360,204 "BMW X3",38000,3,260,180 "BMW X5",45900,3,260,191 "BMW Z4",36400,3,215,161 "Buick Enclave",32055,3.6,275,201 "Buick LaCrosse",22350,3.6,200,198 "Buick Lucerne",25660,3.8,197,203 "Buick Terraza",26660,3.9,240,205 "Cadillac CTS",29825,2.8,210,190 "Cadillac CTS-V",51325,6,400,190 "Cadillac DTS",41390,4.6,275,208 "Cadillac Escalade",53975,6.2,403,203 "Cadillac SRX",37100,3.6,255,195 "Cadillac STS",42250,3.6,255,196
データの読み込み
- 上のデータをコピペして、メモ帳開いて「test.csv」とか名前付けてね。
- データを読み込む
> read.csv("test.csv")
- データをオブジェクトに代入
> car<-read.csv("test.csv") > car
注意
- これからやる回帰モデルの作成はいっぱい嘘があります><
- Rでのモデル作成の流れを理解する、ということが目的なのでご勘弁ください
- 満足できない人はデータ解析の履修をお薦めします><
どういうデータか見ていこう
- データがでかくなるとどういうデータなのか理解するだけでも大変。。。
- str関数とかnames関数で分かるよ
> str(car) 'data.frame': 30 obs. of 5 variables: $ car.name : Factor w/ 30 levels "Acura MDX","Acura RDX",..: 1 2 3 4 5 6 7 8 9 10 ... $ low.price : int 39995 32995 45780 33625 28090 25340 28240 39000 41950 68900 ... $ low.displacement: num 3.7 2.3 3.5 3.2 2.4 2 2 3.2 3.2 4.2 ... $ low.horsepower : int 300 240 290 258 205 200 200 265 255 354 ... $ length : int 191 181 194 189 183 169 180 182 194 204 ...
- names関数は頭の名前だけ表示してくれる
> names(car) [1] "car.name" "low.price" "low.displacement" "low.horsepower" [5] "length"
今まで使った手法でデータを眺めてみる
価格の分布
- 密度トレイスを使ってみる
> plot(density(low.price,n=30,window="c"))
できあがり
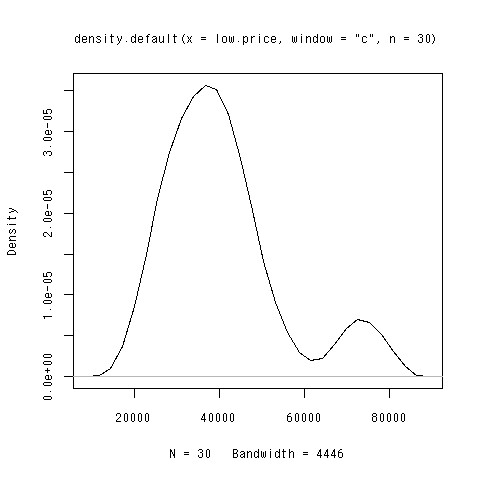
問題点
- バイモーダルな分布
- 右に非常に長くなっている
- 「右にテールが長い」と呼ぶ
- 価格などのデータによく表れる
- 回帰モデルでは
- 従属変数は正規分布を仮定
- 無理矢理作ってもいいモデルはできない。。。
どうしよう?
- 価格を正規分布に従うように変数変換しよう
- いろいろあるんだけど
- logの変換を使います
logの特徴
- 小さい値はそんなに小さくせず
- 大きい値はうんと小さくする
変換の方法
> plot(density(log(low.price),n=30,window="c"))
変換後
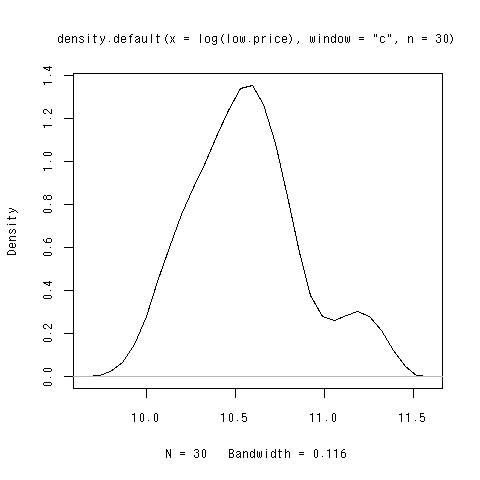
これはどうなの?
- バイモーダルな分布はそのまま><
- 若干右があれな気がするけど、これくらいなら正規分布に従うとみなす
- 本当はだめ!!
- 二つの分布からなっているような場合、それぞれでモデル構築などを行うなどが正しいやり方(と思う)
- でも、今回は端折るから、このままで行くよ><
- log以外の方法
- 「これじゃまだだめだ!!」とか思う人は指数変換などを行ってください
データにlogで変換したやつを入れよう
> car$log.low.price<-log(low.price) > car
回帰モデルを作る
- 正確にはいろいろあるのですが、今回は無視!!
- 問題ありまくりです
- どうしたらいいのか、興味あるひとはデータ(ry
回帰モデルを作るときの関数lm()
- lm(従属変数 ~ 説明変数1+説明変数2+…)
> lm(log.low.price ~ low.displacement+low.horsepower+length) Call: lm(formula = log.low.price ~ low.displacement + low.horsepower + length) Coefficients: (Intercept) low.displacement low.horsepower length 9.168009 -0.127766 0.005947 0.001364
解説
- call
- 回帰モデルの式
- Coefficients
- それぞれに付く係数
もっと知りたい
- lm関数の結果にsummary関数を使おう
回帰モデルの精度
- こんな風にやってね><
> summary(lm(log.low.price ~ low.displacement+low.horsepower+length)) Call: lm(formula = log.low.price ~ low.displacement + low.horsepower + length) Residuals: Min 1Q Median 3Q Max -0.24240 -0.14046 -0.01359 0.12923 0.35671 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 9.168009 0.610076 15.028 2.47e-14 ****** low.displacement -0.127766 0.071036 -1.799 0.0837 . low.horsepower 0.005947 0.001043 5.703 5.31e-06 ****** length 0.001364 0.003434 0.397 0.6945 --- Signif. codes: 0 '******' 0.001 '****' 0.01 '**' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.1681 on 26 degrees of freedom Multiple R-Squared: 0.7308, Adjusted R-squared: 0.6997 F-statistic: 23.53 on 3 and 26 DF, p-value: 1.413e-07
意味を読み取る
- Pr(>|t|)
- 係数が有意なものか
- 「.」くらいで採用。印が付いてないものはほぼ0となり、意味がない。
- Multiple R-Squared
- R^2のこと
- Adjusted R-squared
- 自由度修正済R^2のこと
- 重回帰では普通、自由度修正済R^2を見ていく
- R^2は説明変数の数を増やすだけで上がってしまうから
- 詳しいことは統計勉強会のほうでどうぞ><
結果より
- Lengthは意味ないっぽいね
- (本当はこんなやり方しちゃダメだよ!!)
- Length抜いてやってみる
> summary(lm(log.low.price ~ low.displacement+low.horsepower)) Call: lm(formula = log.low.price ~ low.displacement + low.horsepower) Residuals: Min 1Q Median 3Q Max -0.22739 -0.14040 -0.01975 0.13339 0.36024 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 9.4036720 0.1395729 67.375 < 2e-16 ****** low.displacement -0.1118650 0.0577571 -1.937 0.0633 . low.horsepower 0.0058242 0.0009801 5.942 2.46e-06 ****** --- Signif. codes: 0 '******' 0.001 '****' 0.01 '**' 0.05 '.' 0.1 ' ' 1 Residual standard error: 0.1654 on 27 degrees of freedom Multiple R-Squared: 0.7292, Adjusted R-squared: 0.7091 F-statistic: 36.35 on 2 and 27 DF, p-value: 2.195e-08
検定の方法
- モデルの検定の方法はいろいろあるのだけど、統計の話とも近くなるのでこの辺で
- ちなみに
- モデルの説明力と説明変数の数→Cpプロット
- 価格の残差が正規分布に従っているか→Q-Qプロット
- 分散の不均一性
- これ以上詳しいことはデータ(ry
それ以外のトピック
- 関数の生成
- t検定
- 行列演算
関数
- Rでは自分で関数を作れるよ
- 引数を二乗する関数jijyouを作ってみる
jijyou<-function(i){ return (i^2) } > jijyou(9) [1] 81
- ちなみにベクトルを入れてみる
> jijyou(c(1,2,3,4)) [1] 1 4 9 16
ちょっとオプショナル話
- ディフォルト引数というのが取れるよ
- 何も指定しないということ
jijyou<-function(i=99){ return (i^2) } > jijyou() [1] 9801 > jijyou(9) [1] 81
t検定
- データを生成
> weight<-c(56,60,66,58,61)
- 体重の平均が60キロと等しいか検定したい
- t.test関数で一撃
t.test関数
> t.test(weight,mu=60) One Sample t-test data: weight t = 0.1187, df = 4, p-value = 0.9113 alternative hypothesis: true mean is not equal to 60 95 percent confidence interval: 55.52105 64.87895 sample estimates: mean of x 60.2
見方
- p-value=0.9113
- これが0.05より大きいと有意差がある
- 平均値が60キロであるという帰無仮説は棄却される
- そもそもt検定が…という人は統計勉強会に行きましょう><
次回以降予定
- Rのデータハンドリング
- Rのデータ型
- Rで数理統計学
- Rでデータマイニング